第5章 写缓存
第4章详细讨论了缓存的架构方案,它可以减少数据库读操作的压力,却也存在着不足,比如写操作并发量大时,这个方案不会奏效。那该怎么办呢?本章就来讨论怎么处理写操作并发量大的场景。
5.1 业务场景:如何以最小代价解决短期高频写请求
某公司策划了一场超低价预约大型线上活动,在某天 9:00~9:15 期间,用户可以前往详情页半价预约抢购一款热门商品。根据市场部门的策划方案,这次活动的运营目标是几十万左右的预约量。
为避免活动上线后出现问题,项目组必须提前做好预案。这场活动中,领导要求在架构上不要做太大调整,毕竟是一个临时的活动。
问题分析
项目组通过如下逻辑做了一次简单的测算:
| 指标 | 数值 |
|---|---|
| 目标预约量 | 100万(15分钟内) |
| 峰值预估 | 1分钟内完成90%(90万预约) |
| 目标TPS | 90万/60秒 = 1.5万 |
| 实际压测TPS | 2200左右 |
差距较大!项目组想过分表分库这个方案,不过代码改动的代价太大了,性价比不高。毕竟这次仅仅是临时性市场活动。
解决方案
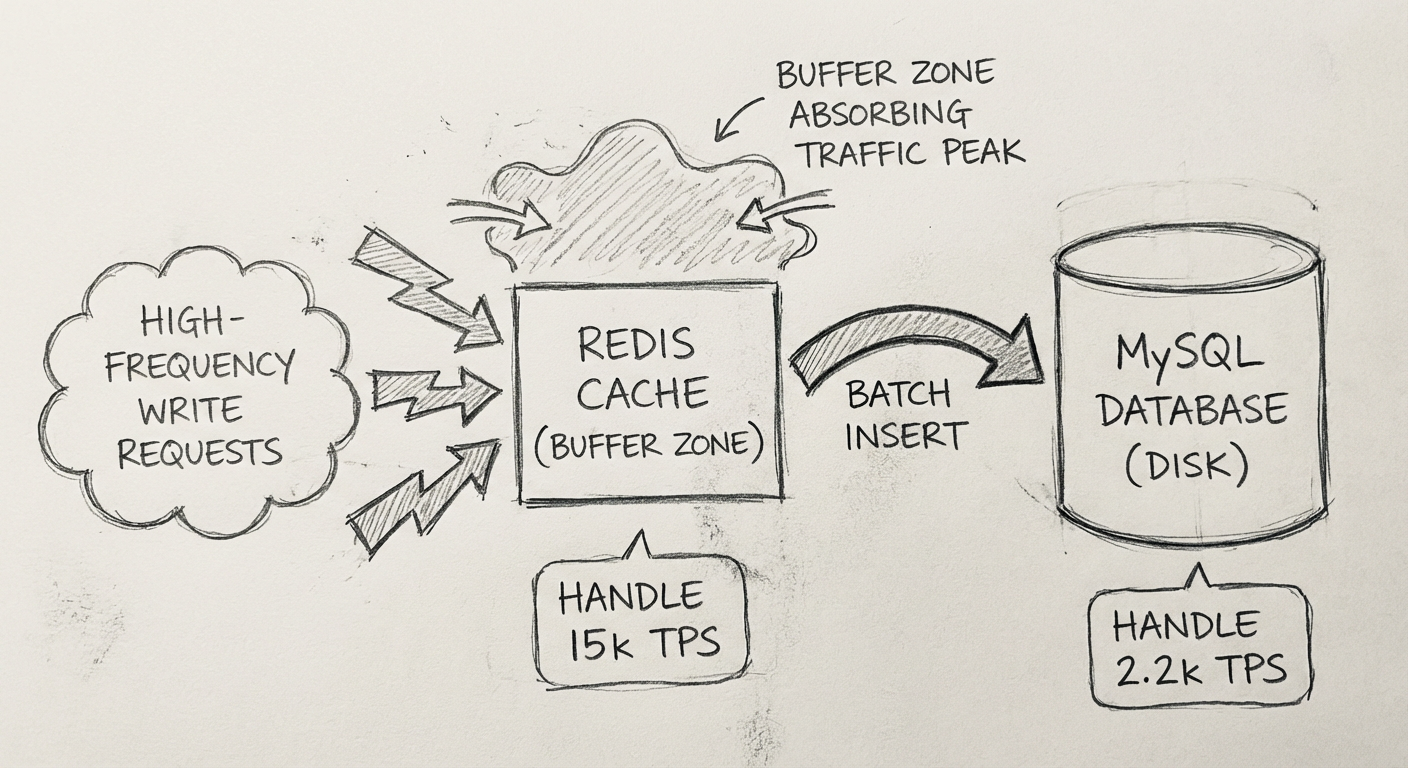
项目最终采用的方案是不让预约的请求直接插入数据库,而是先存放到性能很高的缓冲地带,以此保证洪峰期间先冲击缓冲地带,之后再从缓冲地带异步、匀速地迁移数据到数据库中。
5.2 什么是写缓存
写缓存的思路是后台服务接收到用户请求时,如果请求校验没问题,数据并不会直接落库,而是先存储在缓存层中,缓存层中写请求达到一定数量时再进行批量落库。
它的意义在于:
- 利用写缓存比数据库高几个量级的吞吐能力来承受洪峰流量
- 再匀速迁移数据到数据库
设想的运行场景
假设高峰期 1 秒内有 1.5 万个预约数据的插入请求:
- 这 1.5 万个请求如果直接到数据库,数据库肯定崩溃
- 把这 1.5 万个请求落到并发写性能很高的缓存层
- 然后以 2000 为单位从缓存层批量落到数据库
- 数据库如果用批量插入语句,TPS 可达上万
5.3 实现思路
该方案在具体实施过程中要考虑 6 个问题:
- 写请求与批量落库这两个操作同步还是异步?
- 如何触发批量落库?
- 缓冲数据存储在哪里?
- 缓存层并发操作需要注意什么?
- 批量落库失败了怎么办?
- Redis 的高可用配置
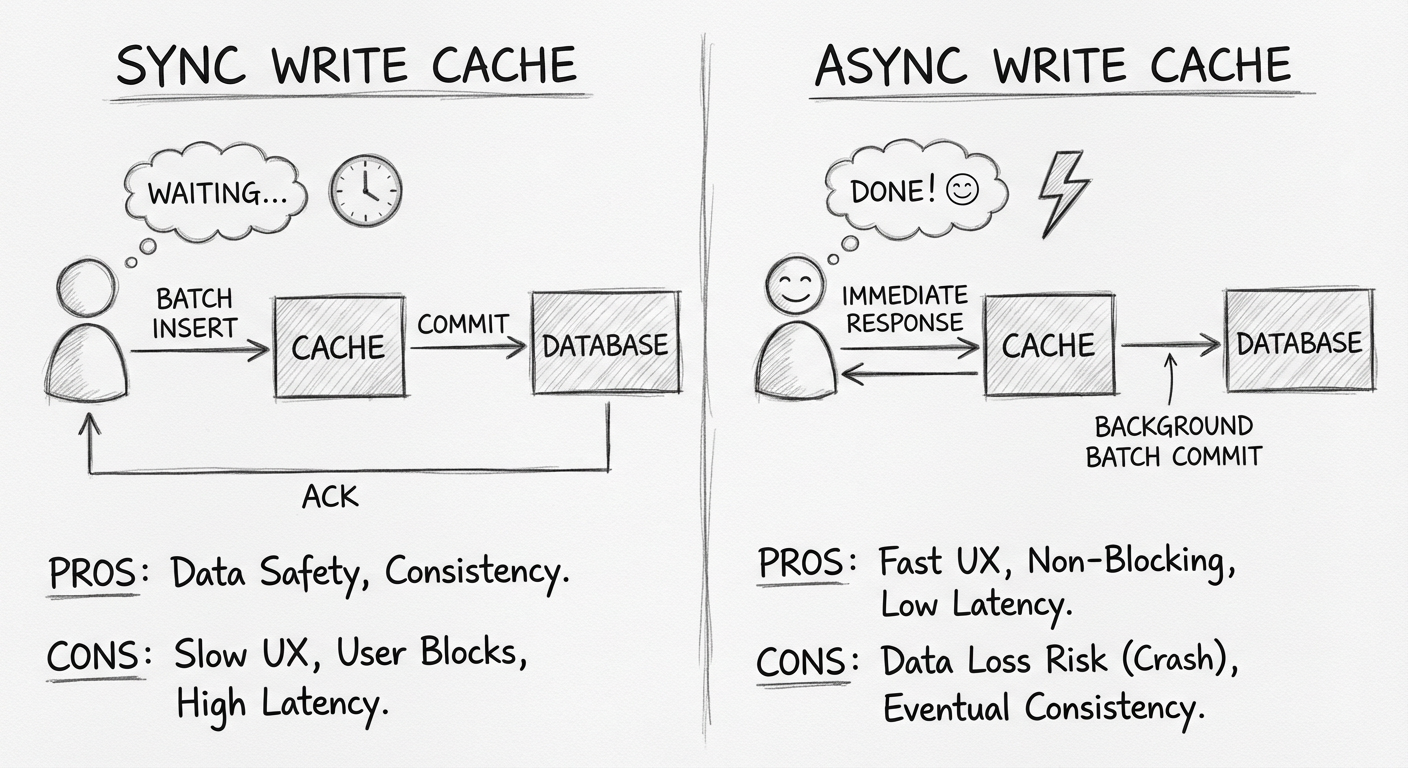
5.3.1 写请求与批量落库:同步还是异步
| 方式 | 优点 | 缺点 |
|---|---|---|
| 同步 | 用户预约成功后可立即看到数据 | 用户需等待一段时间才能返回结果 |
| 异步 | 用户能快速知道提交结果 | 查看"我的预约"可能暂时没有数据 |
同步实现的复杂度更高,需要考虑:
- 用户等待多久?需设置时间窗(如每隔100毫秒批量落库)
- 批量落库超时怎么办?需设置超时时间
- 批量落库失败怎么办?是否重试?多久重试?
因此项目直接选用异步的方式,预约数据保存到缓存层即可返回结果。
用户体验设计方案:
- 在"我的预约"页面给用户一个提示:您的预约订单可能会有一定延迟
- 用户预约成功后进入等待页面,定时轮询后台落库状态(推荐)
5.3.2 如何触发批量落库
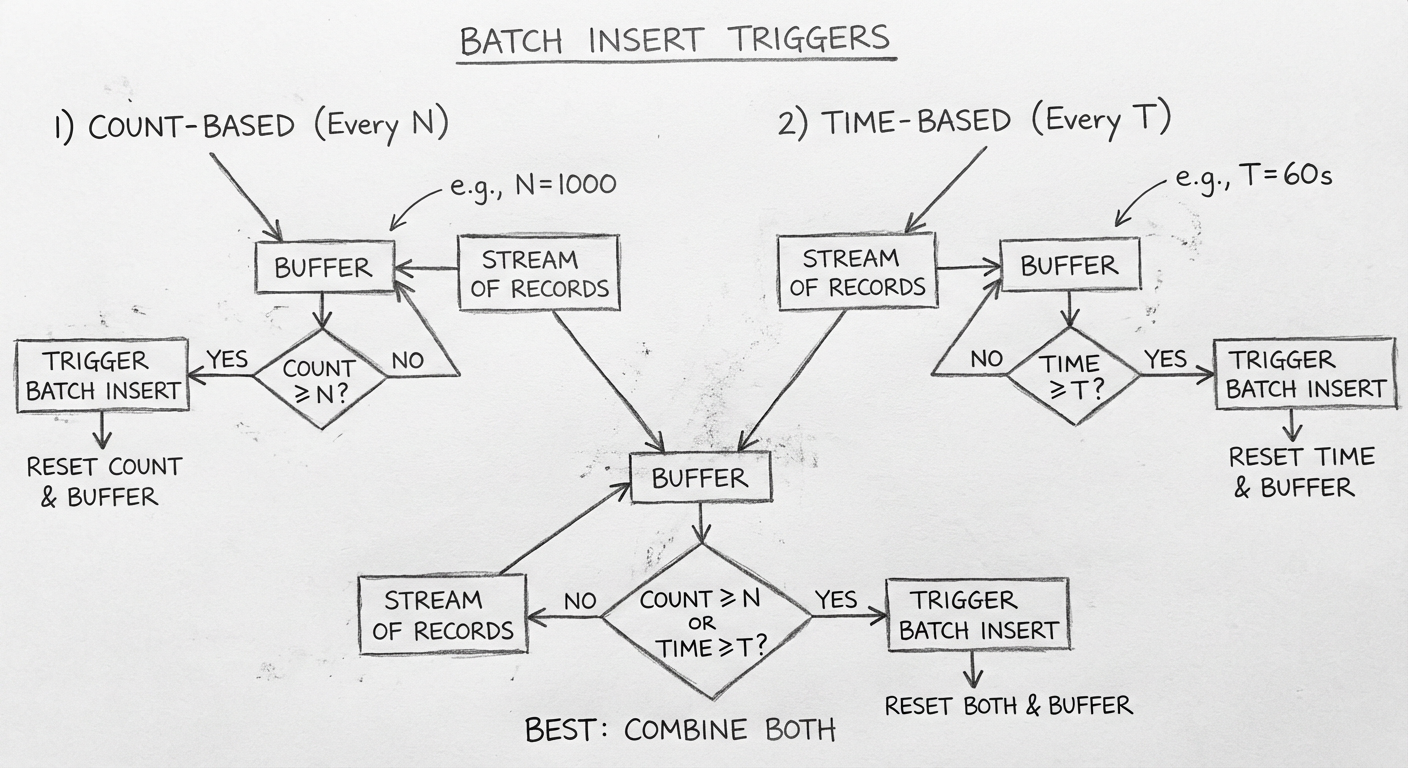
| 触发方式 | 优点 | 缺点 |
|---|---|---|
| 满足特定次数后落库 | 访问数据库次数变为1/N | 未凑齐N次时无法落库 |
| 每隔一个时间窗口落库 | 保证用户等待时间不会太久 | 瞬间流量大时,数据可能堆积 |
最终方案:同时使用这两种方式
具体实现逻辑:
- 每收集一次写请求,就插入预约数据到缓存中
- 判断缓存中预约的总数是否达到一定数量,达到后直接触发批量落库
- 开一个定时器,每隔一秒触发一次批量落库
5.3.3 缓存数据存储在哪里
缓存数据可以存放在:
- 本地内存:简单,但服务器宕机数据会丢失
- MQ:削峰的主要用途,很适合这种场景
- Redis:服务本身已依赖,且易于批量获取数据(本项目选择)
写请求需要考虑容灾问题:如果服务器宕机,内存数据就会丢失,用户的预约数据也就没有了。
5.3.4 缓存层并发操作需要注意什么
根据 MySQL 官方文档关于 Concurrent Insert 的描述:
如果多个 Insert 语句同时执行,它们会根据排队情况按顺序执行,也可以与 Select 语句并发执行。
所以多个 Insert 语句并行执行的性能未必会比单线程 Insert 更快。
在这个场景中,每隔一秒或数据量凑满 10 条就会自动迁移一次,所以一次批量插入操作就能轻松解决,只需要在并发性的设计方案中保证一次仅有一个线程批量落库即可。
5.3.5 批量落库失败了怎么办
批量落库的实现逻辑:
- 当前线程从缓存中获取所有数据
- 当前线程批量保存数据到数据库
- 当前线程从缓存中删除对应数据(注意:不能直接清空)
各步骤失败时的应对措施:
| 失败步骤 | 应对措施 |
|---|---|
| 第1步失败 | 重试获取 |
| 第2步失败 | 重试保存,注意幂等性 |
| 第3步失败 | 重试删除,保证数据最终一致 |
5.3.6 Redis 的高可用配置
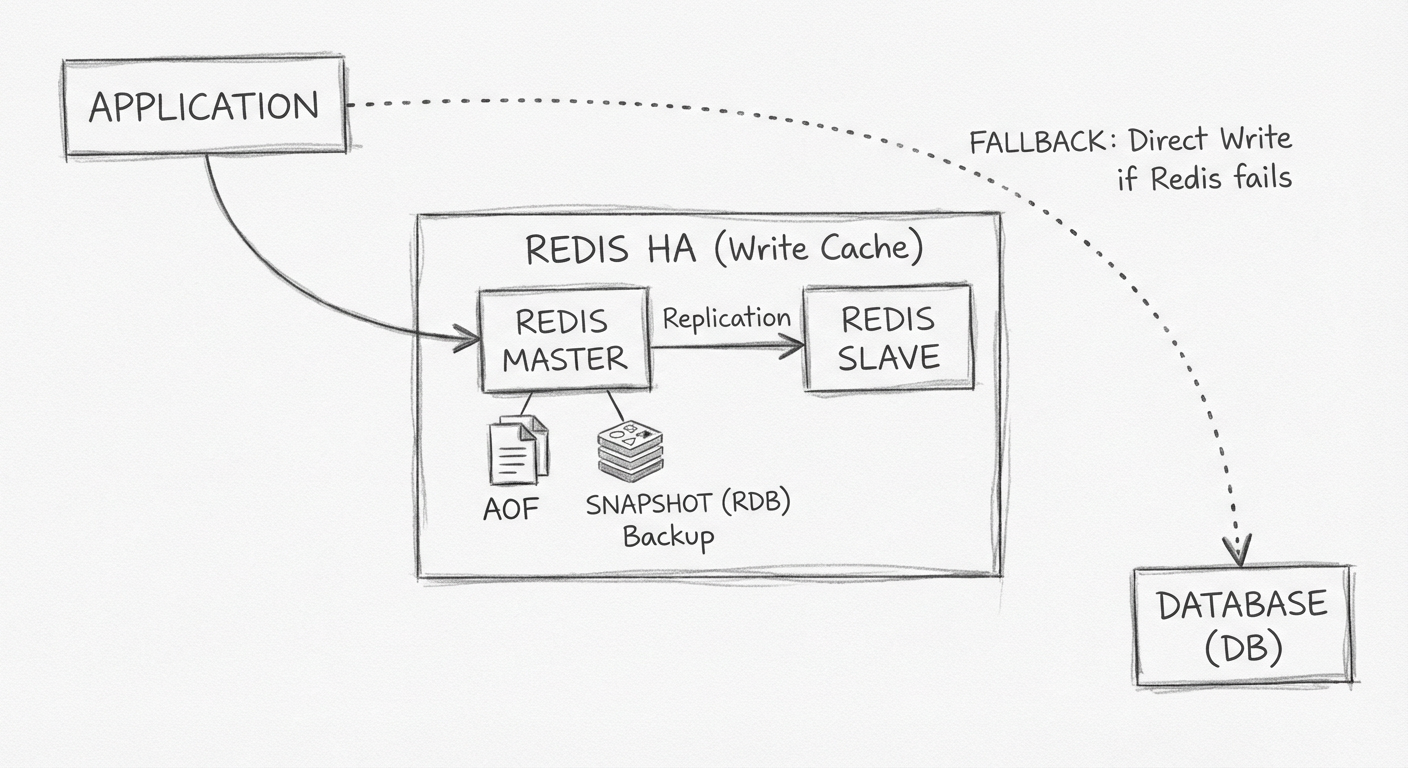
这一业务场景是先把用户提交的数据保存到缓存中,因此必须保证缓存中的数据不丢失。
Redis 支持两种备份方式:
| 方式 | 说明 |
|---|---|
| RDB(快照) | 定时备份,可能丢失最后一次备份后的数据 |
| AOF | 每次操作记录,数据安全性更高 |
最简单的高可用方案:
- 使用简单的主从模式
- 在 Slave Redis 里使用快照(30秒一次)+ AOF(一秒一次)的配置
- 如果 Master Redis 宕机,先把 Slave Redis 升级为 Master Redis
- 代码里有预案:写缓存如果失败直接落库
5.4 小结
这个项目经过两周左右就上线了,上线之后的某次活动中,后台日志和数据库监控一切正常。活动一共收到几十万的预约量,达到了市场预期的效果。
方案不足
写缓存这个解决方案可以缓解写数据请求量太大、压垮数据库的问题,但其不足还是比较明显的:
| 不足 | 说明 | 对应解决方案 |
|---|---|---|
| 只能缓解短时压力 | 长期高并发写数据时无法解决 | 数据收集 |
| 只适合独立写操作 | 如果写操作之间存在竞争资源(如商品库存),此方案无法覆盖 | 秒杀架构 |