第6章 数据收集
上一章详细讨论了写缓存的架构解决方案,它虽然可以减少数据库写操作的压力,但也存在一些不足。比如需要长期高频插入数据时,这个方案就无法满足,接下来将围绕这个问题逐步提出解决方案。
6.1 业务背景:日亿万级请求日志收集如何不影响主业务
因业务快速发展,某天某公司的日活用户高达 500万,基于当时的业务模式,业务侧要求根据用户的行为做埋点,旨在记录用户在特定页面的所有行为,以便开展数据分析,以及与第三方进行费用结算。
业务需求
在数据埋点的过程中,业务侧还要求在后台能准实时查询用户行为数据及统计报表。
需收集的原始数据结构:
| 字段 | 说明 |
|---|---|
| 用户ID | 用户唯一标识 |
| 时间戳 | 事件发生时间 |
| 经纬度 | 用户位置信息 |
| 目标类型 | 页面/按钮/链接等 |
| 目标ID | 具体目标标识 |
| 事件动作 | 点击/浏览/滑动等 |
通过以上数据结构,业务侧可以:
- 将城市、性别、年龄、目标类型、目标ID、事件动作等作为查询条件
- 从时间、性别、年龄等维度查看统计报表
6.2 技术选型思路
根据业务场景,项目组提炼出了 6 点业务需求:
| 业务需求 | 技术选型思路 |
|---|---|
| 原始数据海量 | 使用 HBase 进行持久化 |
| 埋点记录请求响应要快 | 存放到缓存层(本地日志) |
| 可通过后台查询原始数据 | 使用 Elasticsearch 保存查询条件字段 |
| 各种统计报表需求 | 自己设计功能(灵活性高) |
| 根据埋点日志生成费用结算数据 | 保存在 MySQL 中 |
| 需要处理框架将数据迁移到持久化层 | 实时处理工具(Flink) |
6.2.1 使用什么技术保存埋点数据的第一现场
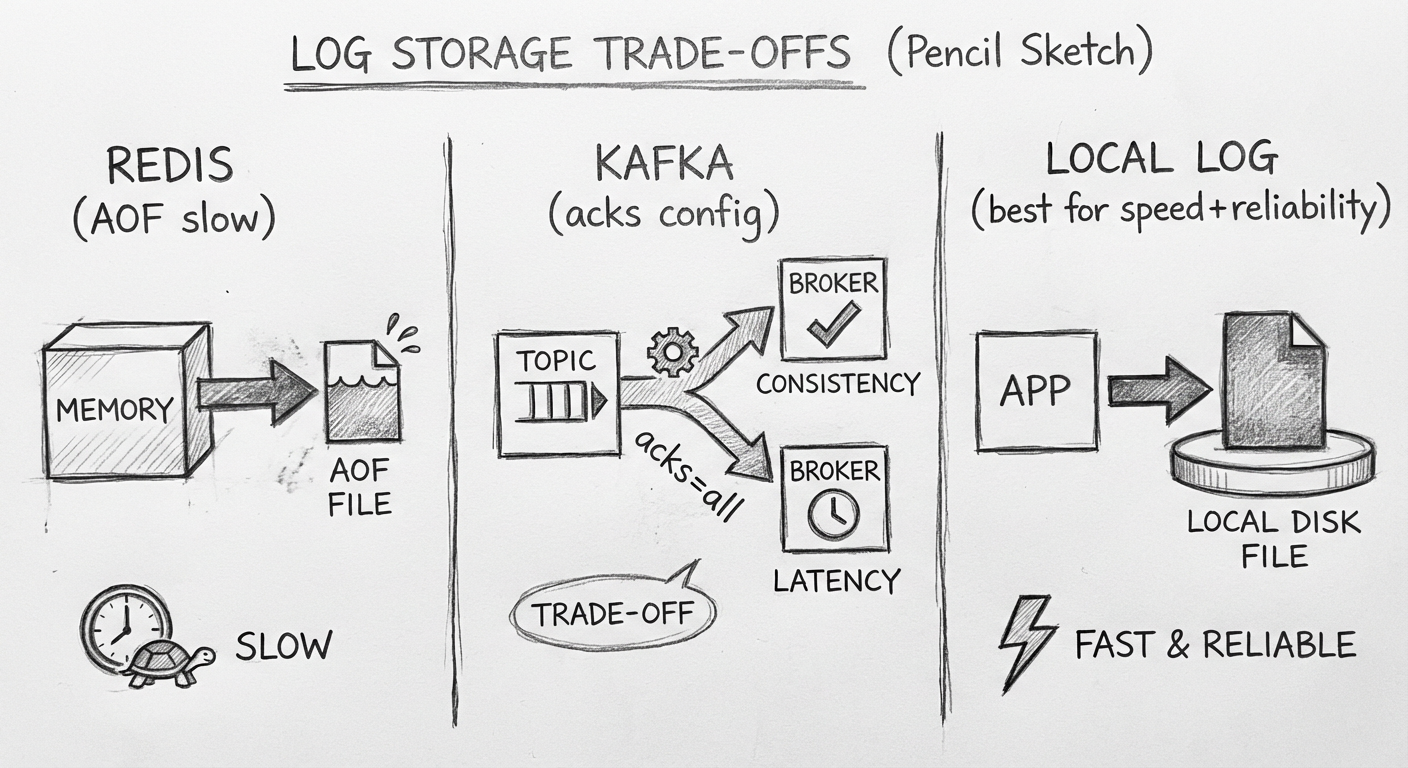
目前快速保存埋点数据的技术主要分为 3 种:
| 技术 | 优点 | 缺点 |
|---|---|---|
| Redis | 读写快 | 需要配置持久化,响应要求高时性能受影响 |
| Kafka | 吞吐量大 | 需要等待数据同步,响应可能变慢 |
| 本地日志 | 响应最快 | 需要额外收集 |
Redis 的 AOF 机制分析:
appendfsync=everysec:每秒落盘一次,可能丢失一秒数据appendfsync=always:每次操作落盘后返回,系统运行会很慢
Kafka 的 acks 配置分析:
acks=0:不等落盘直接返回,响应快但数据无保障acks=1:等 Leader 落盘,不等 Follower 同步acks=all:等所有副本同步,数据有保障但响应慢
最终决定把埋点数据保存到本地日志中——性能和可靠性兼得。
6.2.2 使用什么技术收集日志数据到持久化层
最简单的方式是通过 Logstash 直接把日志文件迁移到 Elasticsearch,但会有问题:
- Elasticsearch 需要包含城市、性别、年龄等业务数据
- 这些数据日志文件中没有,需要调用业务系统获取
不直接使用 Logstash 到持久化层的原因:
- 需要同时输出到 Elasticsearch 和 HBase 两个源,一个出错会影响另一个
- MySQL 中需要动态计算费用结算数据,Logstash 不适用
最终方案:引入计算框架
- 通过 Logstash 把日志文件迁移到 MQ
- 通过实时计算框架处理 MQ 中的数据
- 保存处理后的数据到持久层
Logstash 资源消耗大(Ruby 语言编写),官方推出了轻量化的 Filebeat。但 Filebeat 使用轮询方式采集,存在一定延时,所以该项目最终选择继续使用 Logstash。
6.2.3 为什么使用 Kafka
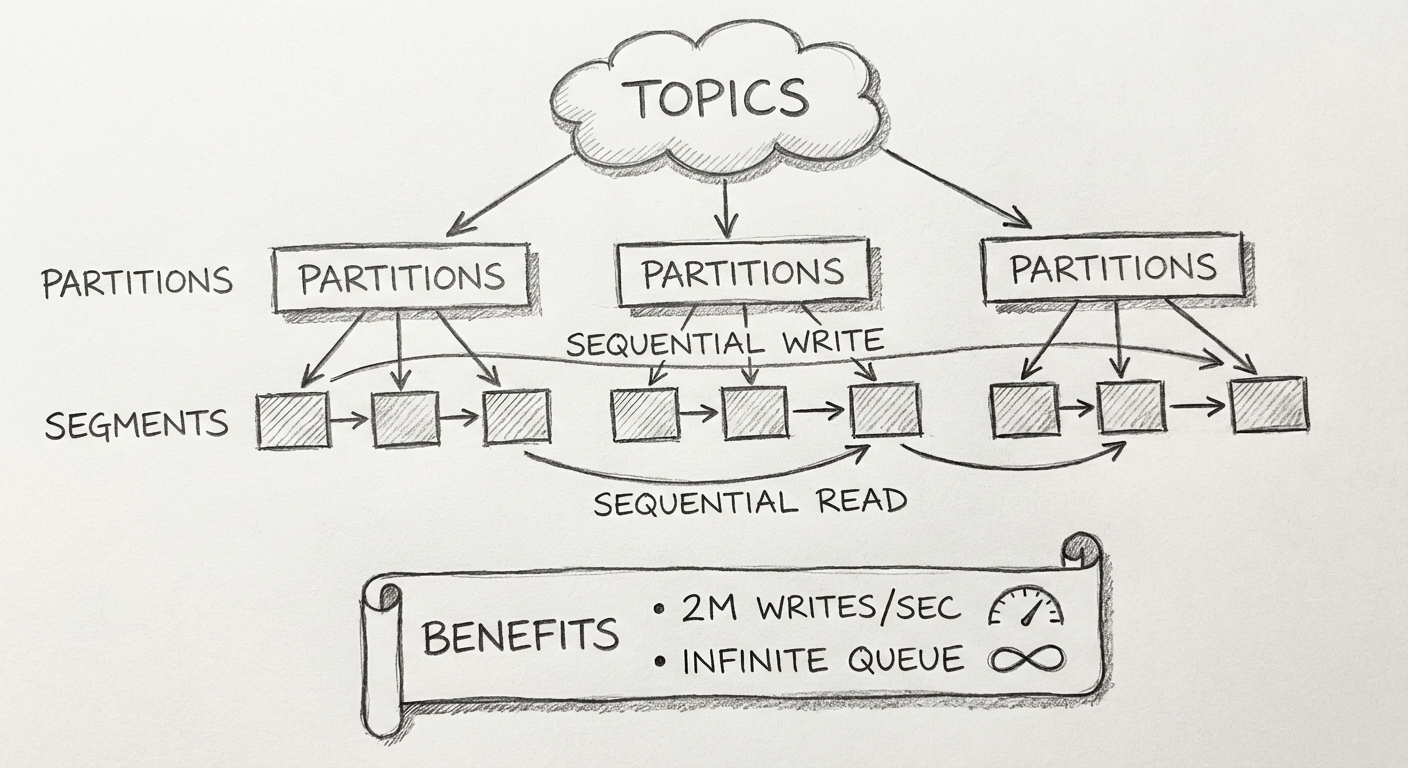
Kafka 是 LinkedIn 推出的开源消息中间件,它天生是为收集日志而设计的,具备:
- 超高吞吐量:3台便宜的机器每秒写入两百万条记录
- 数据量扩展性:被称作无限堆积
Kafka 为什么吞吐量这么高?
Kafka 的存储结构:
- 每个 Topic 分区相当于一个巨型文件
- 每个巨型文件由多个 Segment 小文件组成
- Producer 负责对该巨型文件进行"顺序写"
- Consumer 负责对该文件进行"顺序读"
好处:读操作不会阻塞写操作,这也是其吞吐量大的原因。
6.2.4 使用什么技术把 Kafka 的数据迁移到持久化层
需要使用一个分布式实时计算框架,原因有两点:
- 数据量特别大,需要多个节点并发处理
- 业务要求实时查询统计报表数据
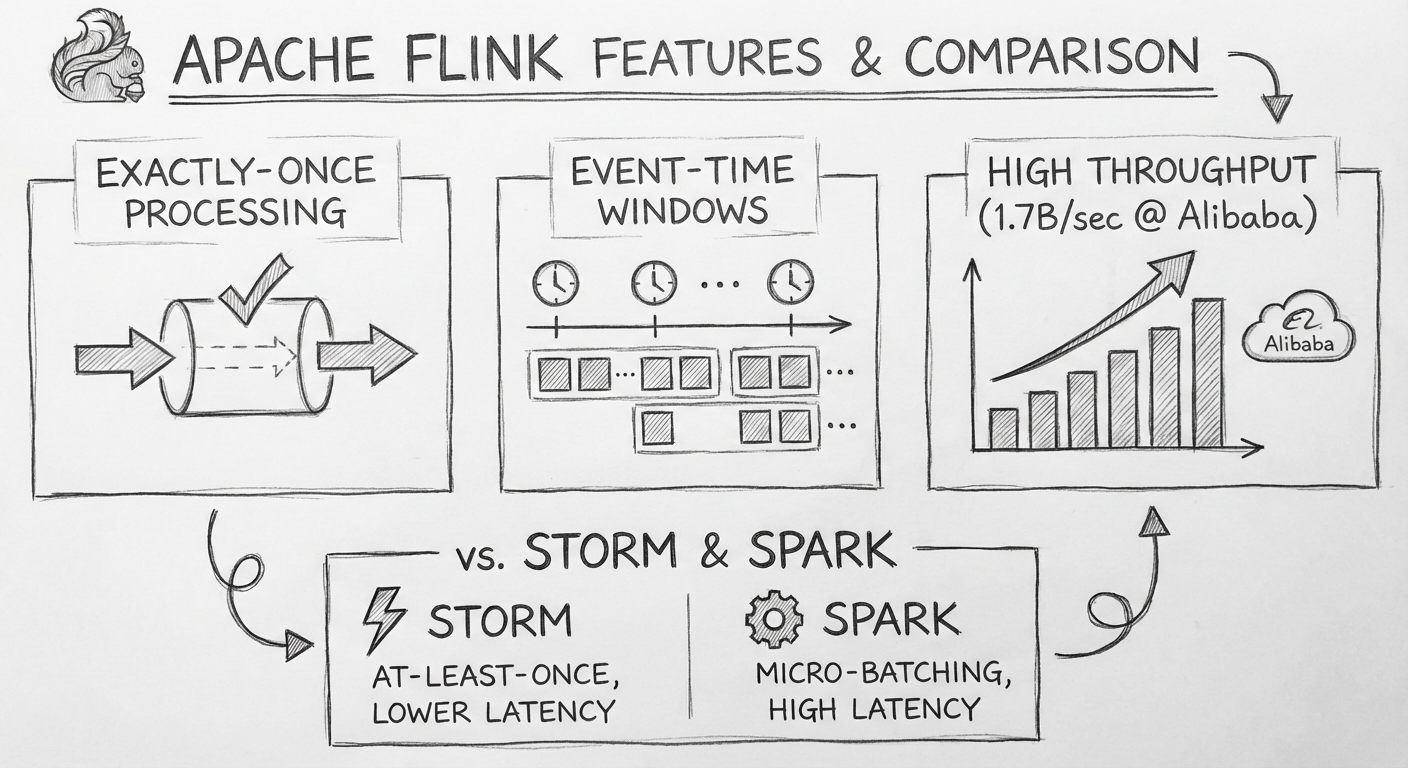
目前流行的分布式实时计算框架:
| 框架 | 特点 |
|---|---|
| Storm | 最早的流处理框架 |
| Spark Streaming | 微批处理 |
| Apache Flink | 性能强、容错好、时间窗口支持 |
选择 Apache Flink 的原因:
- 性能强:阿里活动期间一秒内能够处理 17 亿条数据
- 容错机制:能保证每条数据仅仅处理一次(Exactly-Once)
- 时间窗口:基于消息的事件时间,而不是处理时间
流处理的容错机制
| 容错级别 | 说明 |
|---|---|
| At-Most-Once | 至多一次,可能丢失数据 |
| Exactly-Once | 精确一次,最优选择 |
| At-Least-Once | 至少一次,可能重复消费 |
时间窗口计算
日志中事件发生的时间可能与计算框架处理消息的时间不一致。
示例:一条消息事件时间是 6:30,处理时间延后 2 秒变成 6:32
- 如果按处理时间统计 6:01~6:30 的数据,这条消息不会被计算在内
- Apache Flink 使用事件时间,确保统计准确
6.3 整体方案
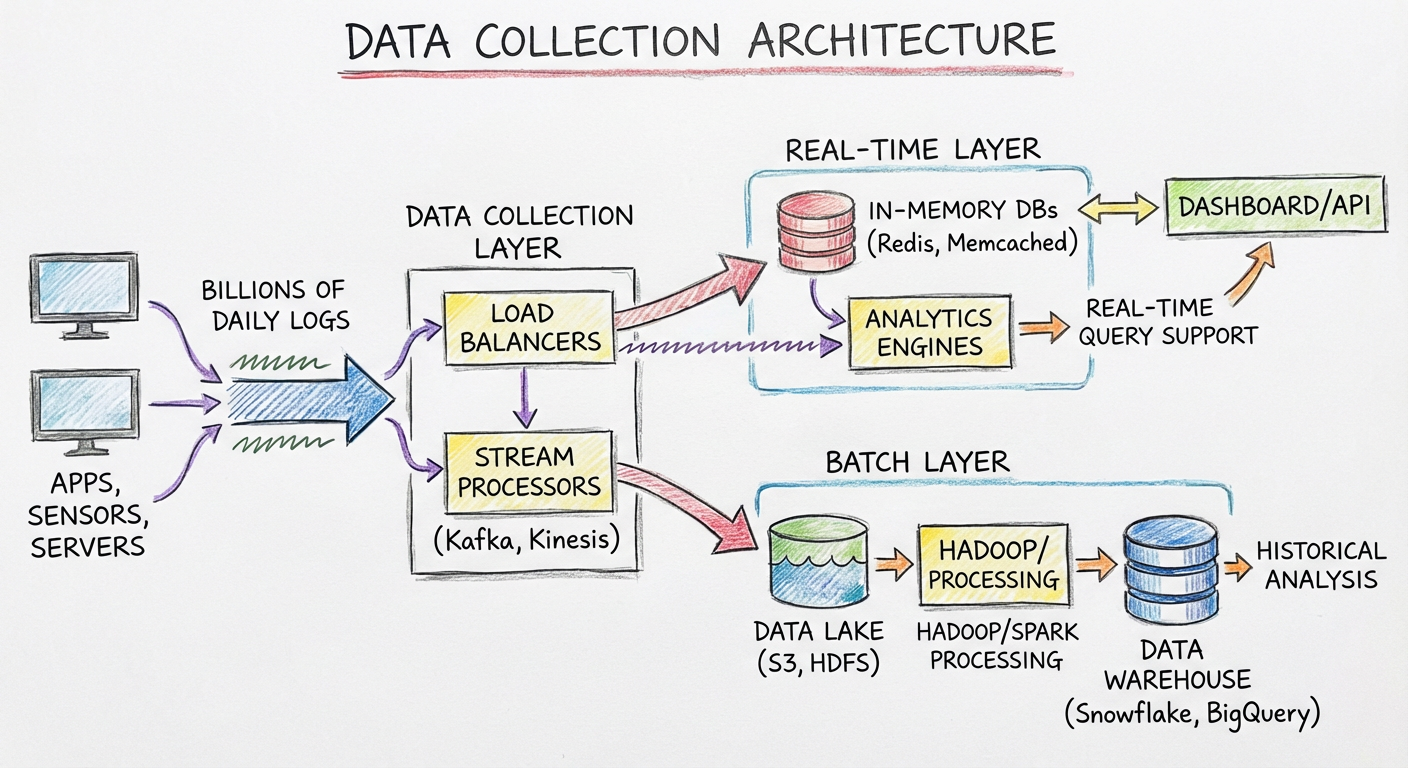
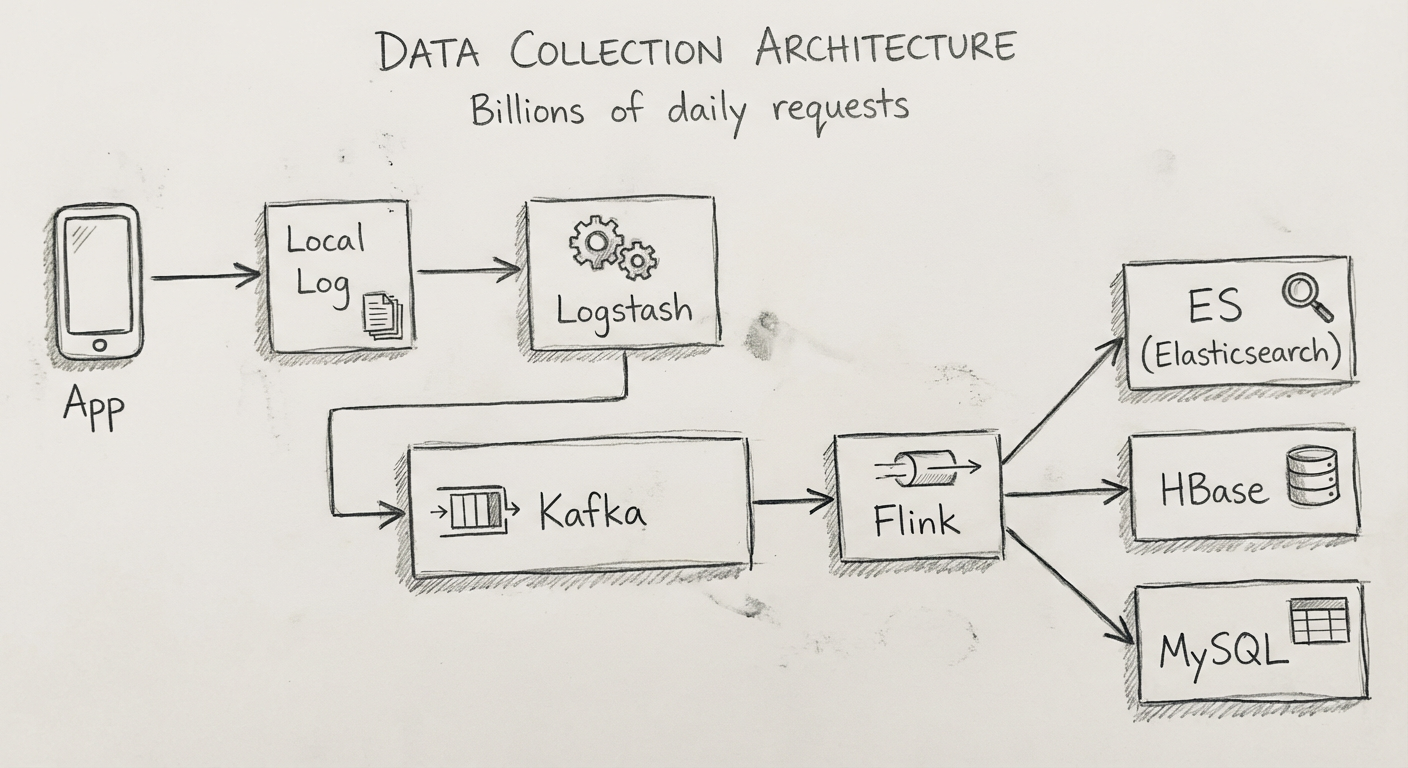
整个架构的流程如下:
- 后台服务端记录所有的请求数据,存放到本地的日志文件
- 使用数据收集框架 Logstash,从日志文件抽取原始的日志数据,不加工直接存放到 Kafka
- 通过 Apache Flink 从 Kafka 中拉取原始的日志数据,并且经过业务加工
- 分别存放到 Elasticsearch、HBase 和 MySQL 中
各存储的用途:
| 存储 | 用途 |
|---|---|
| Elasticsearch | 处理用户针对请求日志的查询请求,存放查询关键字段和请求ID |
| HBase | 存放详细的请求数据 |
| MySQL | 存放组合加工后的结算数据 |
查询流程:
- 根据查询关键字在 Elasticsearch 中获得结果 ID 列表
- 通过结果 ID 去 HBase 中获取详细的请求数据
6.4 小结
本章并没有讲解特别深入的架构设计方面的注意事项,而是主要阐述技术选型背后的思考过程。
学架构的过程就是经历一些基础的场景,而那些复杂的场景其实是简单场景的叠加复用。
方案落地后的效果:
- 丢数据的情况并不多
- 架构的扩展性很好
- 之后日活达到了几千万,系统仍然可以使用(需多加机器,定时清理旧数据)
写缓存解决的问题回顾
| 问题 | 解决章节 |
|---|---|
| 长期高并发写数据 | 本章已解决 |
| 高并发且请求需要抢资源 | 秒杀架构 |