第1章 冷热分离
本书讲的第一个场景是冷热分离。简单来说,就是将常用的"热"数据和不常使用的"冷"数据分开存储。本章要考虑的重点是锁的机制、批量处理以及失败重试的数据一致性问题。这部分内容在实际开发中的"陷阱"还是不少的。
1.1 业务场景:几千万数据量的工单表如何快速优化
这次项目优化的是一个邮件客服系统。它是一个 SaaS(通过网络提供软件服务)系统,但是大客户只有两三家,最主要的客户是一家大型媒体集团。
这个系统的主要功能是:它会对接客户的邮件服务器,自动收取发到几个特定客服邮箱的邮件,每收到一封客服邮件,就自动生成一个工单。之后系统就会根据一些规则将工单分派给不同的客服专员处理。
这个系统是支持多租户的,每个租户使用自己的数据库(MySQL)。
这家媒体集团客户两年多产生了近 2000万 的工单,工单的操作记录近 1亿。平时客服在工单页面操作时,打开或者刷新工单列表需要 10秒钟 左右。

项目组详细分析了当时的数据状况:
| 数据项 | 数据量 |
|---|---|
| 工单表 | 3000万条数据 |
| 工单处理记录表 | 1.5亿条数据 |
| 每日新增工单 | 10万条 |
当时系统性能已经严重影响了客服的处理效率,需要放在第一优先级解决,客户给的期限是 1周。
在客户提出需求之前,项目组已经通过优化表结构、业务代码、索引、SQL语句等办法来提高系统响应速度,但这次只能尝试其他方案。
1.2 数据库分区,从学习到放弃
什么是数据库分区
分区并不是生成新的数据表,而是将表的数据均衡分配到不同的硬盘、系统或不同的服务器存储介质中,实际上还是一张表。
数据库分区有以下优点:
- 存储扩展:比起单个文件系统或硬盘,分区可以存储更多的数据
- 数据清理:在清理数据时,可以直接删除废弃数据所在的分区
- 查询优化:可以大幅度地优化特定的查询,让这些查询语句只去扫描特定分区的数据
为什么放弃数据库分区
通过跟客服的交流,项目组发现:
- 一般工单被关闭以后,客服查询的概率就很低了
- 对于那些关闭超过一个月的工单,基本上一年都打开不了几次
调研到这里,基本的思路是增加一个状态:归档。但相关开发人员并没有用过数据库分区功能,而当时只有 1 周的时间来解决问题,工单表是系统最核心的数据表,不能出问题。
因此,项目组放弃了数据库分区,并决定基于同样的分区理念,使用自己熟悉的技术来实现这个功能:
- 新建一个冷数据库,将 1 个月前已经完结的工单数据都移动到这个新的数据库
- 当前的数据库保留热数据,保留正常处理的较新的工单数据
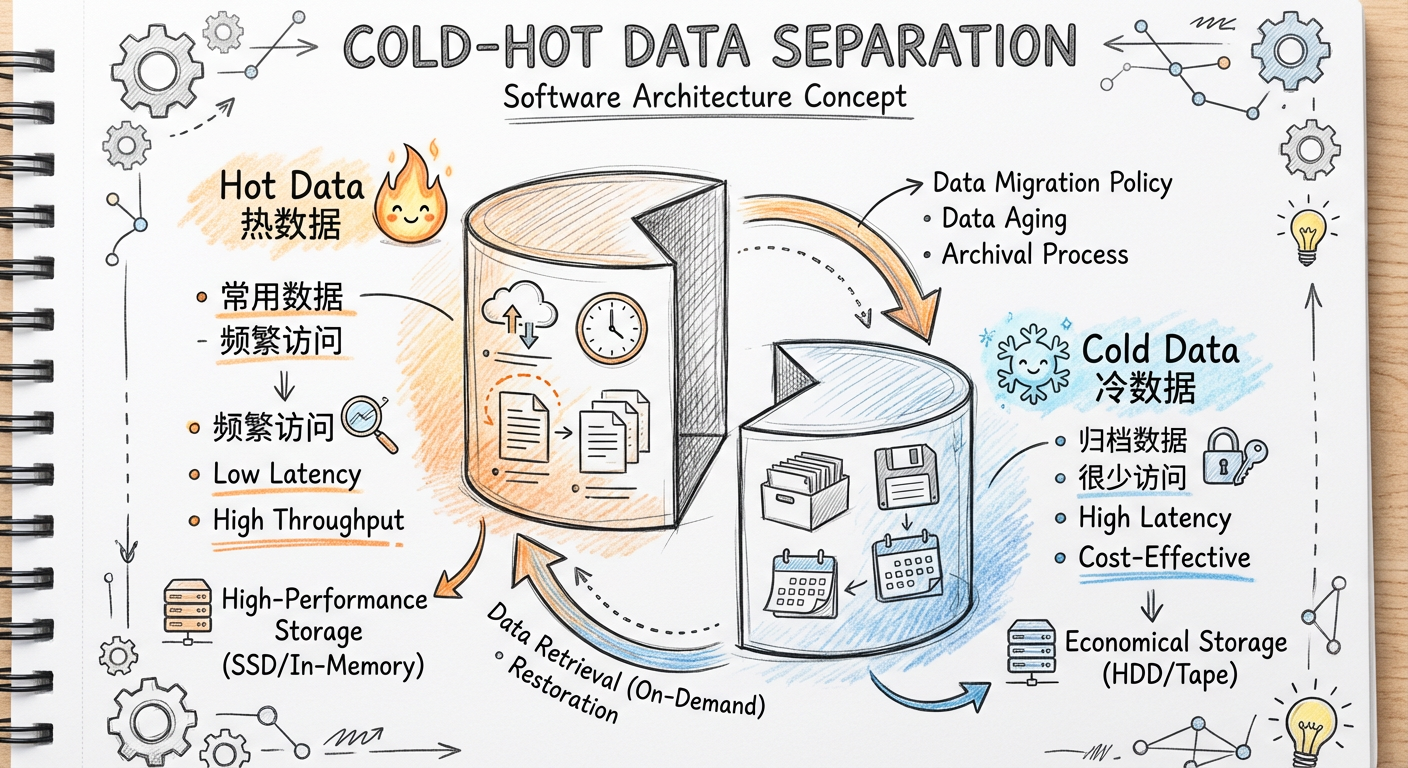
1.3 冷热分离简介
1.3.1 什么是冷热分离
冷热分离就是在处理数据时将数据库分成冷库和热库:
- 冷库:存放那些走到终态、不常使用的数据
- 热库:存放还需要修改、经常使用的数据
1.3.2 什么情况下使用冷热分离
假设业务需求出现了以下情况,就可以考虑使用冷热分离的解决方案:
- 数据走到终态后只有读没有写的需求,比如订单完结状态
- 用户能接受新旧数据分开查询,比如有些电商网站默认只让查询 3 个月内的订单
1.4 冷热分离一期实现思路:冷热数据都用 MySQL
冷热分离一期有一个主导原则:热数据跟冷数据使用一样的存储(MySQL)和数据结构,这样工作量最少。
在冷热分离一期的实际操作过程中,需要考虑以下问题:
- 如何判断一个数据是冷数据还是热数据?
- 如何触发冷热数据分离?
- 如何实现冷热数据分离?
- 如何使用冷热数据?
- 历史数据如何迁移?
1.4.1 如何判断一个数据到底是冷数据还是热数据
一般而言,主要采用主表里一个字段或多个字段的组合作为区分标识:
| 维度 | 示例 |
|---|---|
| 时间维度 | 把 3 个月前的订单数据当作冷数据 |
| 状态维度 | 将已完结的订单当作冷数据 |
| 组合字段 | 下单时间小于 3 个月且状态为"已完结"的订单 |
关于判断冷热数据的逻辑,有两个要点必须说明:
- 如果一个数据被标识为冷数据,业务代码不会再对它进行写操作
- 不会同时存在读取冷、热数据的需求
1.4.2 如何触发冷热数据分离
一般来说,冷热数据分离的触发逻辑分为 3 种:
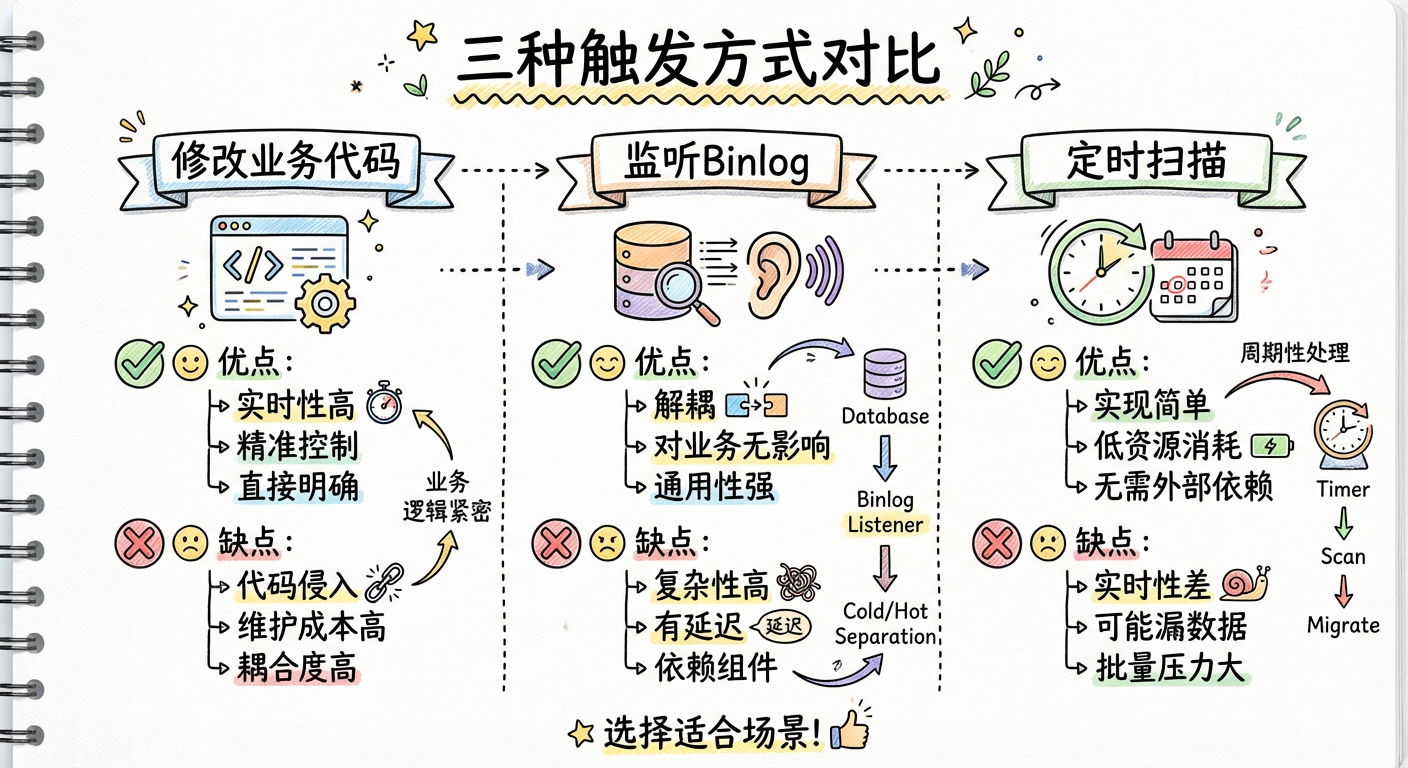
1. 直接修改业务代码
每次修改数据时触发冷热分离(比如每次更新订单的状态时,就去触发这个逻辑)。
适用场景:业务代码比较简单,并且不按照时间区分冷热数据时使用。
2. 监听数据库变更日志(binlog)
另外创建一个服务,专门用来监控数据库的 binlog,一旦发现表有变动,就将变动的数据发送到队列,触发冷热分离逻辑。
适用场景:业务代码比较复杂,不能随意变更,并且不按时间区分冷热数据时使用。
3. 定时扫描数据库
通过 quartz 配置本地定时任务,或者通过类似于 xxl-job 的分布式调度平台配置定时任务。
适用场景:按照时间区分冷热数据时使用。
| 触发方式 | 优点 | 缺点 |
|---|---|---|
| 修改业务代码 | 实时性高、直接明确 | 代码侵入、维护成本高 |
| 监听 Binlog | 无代码侵入、通用性强 | 复杂性高、需额外部署 |
| 定时扫描 | 无需外部依赖、可靠稳定 | 实时性差、可能数据延迟 |
1.4.3 如何分离冷热数据
分离冷热数据的基本逻辑如下:
- 判断数据是冷是热
- 将要分离的数据插入冷数据库中
- 从热数据库中删除分离的数据
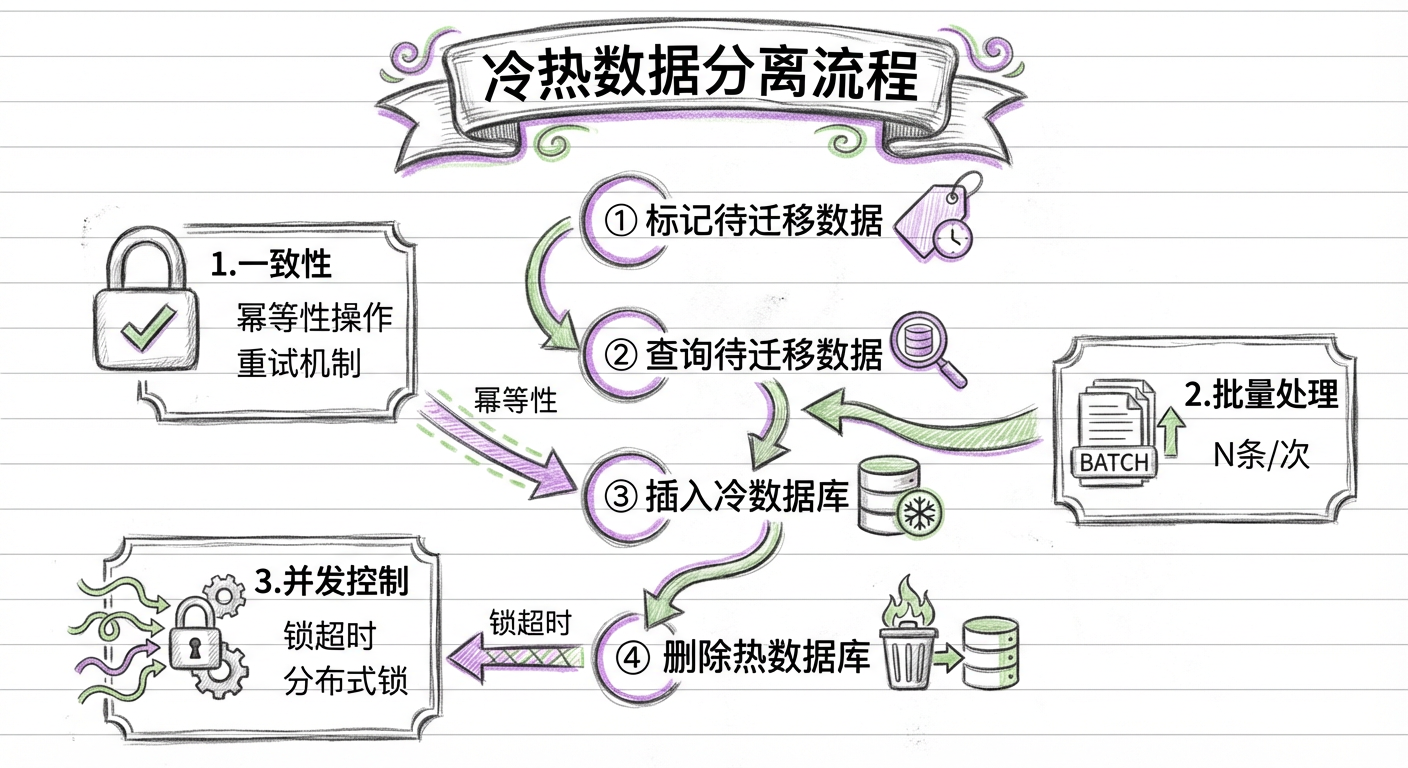
这个逻辑看起来简单,而实际做方案时,以下 3 点都要考虑在内:
1. 一致性:如何保证数据的一致性?
解决方案为保证每一步都可以重试且操作都有幂等性,具体逻辑分为 4 步:
- 标记待迁移数据:在热数据库中给需要迁移的数据加标识
ColdFlag=WaittingForMove - 查询待迁移数据:找出所有待迁移的数据
- 插入冷数据库:在冷数据库中保存一份数据,保存逻辑中需要加判断来保证幂等性
- 删除热数据:从热数据库中删除对应的数据
2. 数据量:是否需要使用批量处理?
如果采用定时扫描的逻辑,就需要考虑数据量问题。实现逻辑:
- 在热数据库中给需要的数据添加标识
- 找出前 1000 条待迁移的数据
- 在冷数据库中保存一份数据
- 从热数据库中删除对应的数据
- 循环执行 2~4
3. 并发性:多线程处理时的锁机制
当采用多线程同时迁移冷热数据时,需要考虑:
获取锁的原子性
使用一条 Update...Where... 语句,利用 MySQL 的更新锁机制来实现原子性:
Update Set LockThread=当前线程ID, LockTime=当前时间
Where LockThread为空 Or LockTime<N秒
锁超时处理
给锁设置一个合理的超时时间,如果锁超时了还未释放,其他线程可正常处理该数据。
幂等性保证
使用 MySQL 的 Insert...On Duplicate Key Update 语句实现幂等操作。
1.4.4 如何使用冷热数据
在功能设计的查询界面上,一般都会有一个选项用来选择需要查询冷数据还是热数据。
在判断是冷数据还是热数据时,必须确保用户没有同时读取冷热数据的需求。
1.4.5 历史数据如何迁移
因为前面的分离逻辑在考虑失败重试的场景时刚好覆盖了这个问题,所以解决方案很简单:只需要批量给所有符合冷数据条件的历史数据加上标识 ColdFlag=WaittingForMove,程序就会自动迁移了。
1.4.6 整体方案
整体解决方案包括 5 个部分:
- 冷热数据判断逻辑:根据业务规则判断数据冷热状态
- 冷热数据的触发逻辑:定时扫描触发
- 冷热数据分离实现思路:批量处理 + 幂等性保证
- 冷热数据库使用:界面提供选择
- 历史数据迁移:标记后自动迁移
这个项目的完成花费了 10 天,上线以后,在客服的常规工单处理页面中,查询基本可以在 1 秒左右完成,大大提升了客服的工作效率。
1.5 冷热分离二期实现思路:冷数据存放到 HBase
1.5.1 冷热分离一期解决方案的不足
冷热分离一期的解决方案虽然能解决写操作慢和热数据慢的问题,但仍然存在诸多不足:
- 用户查询冷数据的速度依旧很慢
- 冷数据库偶尔会告警
归档的数据库里面,工单表仍然有 3000 多万的工单数据,工单处理记录表仍然有数亿的数据。
1.5.2 归档工单的使用场景
对于归档的工单,基本只有以下几个查询动作:
- 根据客户的邮箱查询归档工单
- 根据工单 ID 查出该工单所有的处理记录
这些操作转化成技术需求:
- 可以存放上亿甚至数亿的数据
- 支持简单的组合关键字查询,查询慢一些可以接受
- 存放的数据不再需要变更
最后,项目组决定使用 HBase 来保存归档工单。
1.5.3 HBase 原理介绍
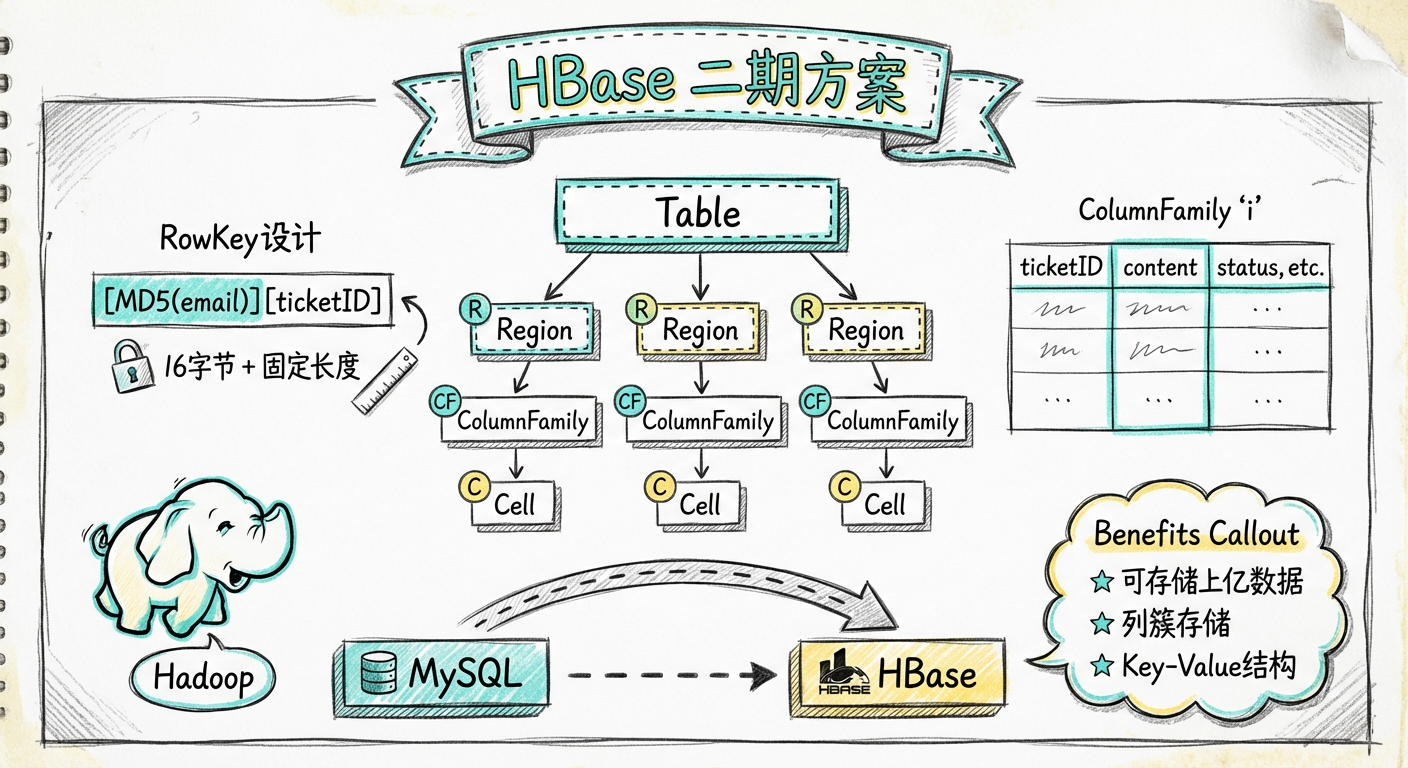
HBase 的基本数据结构
HBase 里面有这些概念:Table、Row、Column、ColumnFamily、ColumnQualifier、Cell、TimeStamp。
- ColumnFamily(列簇):一开始就要定义好,类似于关系型数据库里面的列
- ColumnQualifier(列限定符):每个 ColumnFamily 可以灵活增加,不需要在创建表时定义
- Cell:每一个 RowKey、TimeStamp 以及 Key-Value 值
虽然不同的 ColumnFamily 属于同一个表,但它们物理上是分开存储的。这也是 HBase 的一张表可以存放上百亿数据的原因。但也是因为这个特性,HBase 基本实现不了复杂的查询。
HBase 的物理存储模型
- Region:一个表会被水平切割成多个 Region,每个 Region 会包含多个 Row
- RegionServer:每个 RegionServer 是一个服务器节点,会包含多个 Region(大概 1000 个)
- MemStore:一个 Region 会包含多个 MemStore,每个 MemStore 存储一个 ColumnFamily
- HFile:一个 MemStore 会把数据写入多个 HFile
HBase 的写操作流程
- 客户端访问 ZooKeeper,读取元数据
- 根据 namespace、表名、RowKey 找到数据对应的 Region
- 访问 Region 对应的 RegionServer
- 写入 WAL(Write Ahead Log)
- 写入 MemStore
- 通知客户端写入完成
HBase 的读操作流程
- 客户端访问 ZooKeeper,读取元数据
- 根据 namespace、表名、RowKey 找到数据对应的 Region
- 访问 Region 对应的 RegionServer
- 查找对应的 Region
- 查询 MemStore
- 找到 BlockCache(读缓存)
- 如果没有找到所有的 Cell,则会到多个 HFile 中去查找
1.5.4 HBase 的表结构设计
项目组从 HBase 的说明文档中得出了以下设计要点:
- RowKey 设计:
[MD5(customeremail)][ticketID],前面的邮箱名长度是 16 字节,后面的工单 ID 是固定长度 - ColumnFamily:只使用一个
i(HBase 推荐短列名,省空间) - 工单处理记录:将每个工单下面的处理记录全部序列化成一组 JSON 数据,保存在一个 ColumnKey 中
1.5.5 二期的代码改造
二期和一期的主要区别就是冷数据库使用了 HBase,主要的代码逻辑有一个变化:事务处理。
一期的批量逻辑:
- 取出 300 条工单
- 通过单事务包围的 BATCH SQL 语句插入冷数据库
- 通过单事务包围的 BATCH SQL 语句从热数据库中删除数据
二期的批量逻辑(HBase 不支持类似事务):
- 取出 50 条工单,先处理第一个工单
- 将当前工单的各个 ColumnKey 值插入 HBase
- 通过单事务包围的 SQL 语句删除热数据库中该工单对应的数据
- 循环执行第 2 步和第 3 步
二期花费了 3 周左右才上线,之后查询归档工单的性能好了很多,特别是单个归档工单的打开操作响应快了不少。
1.6 小结
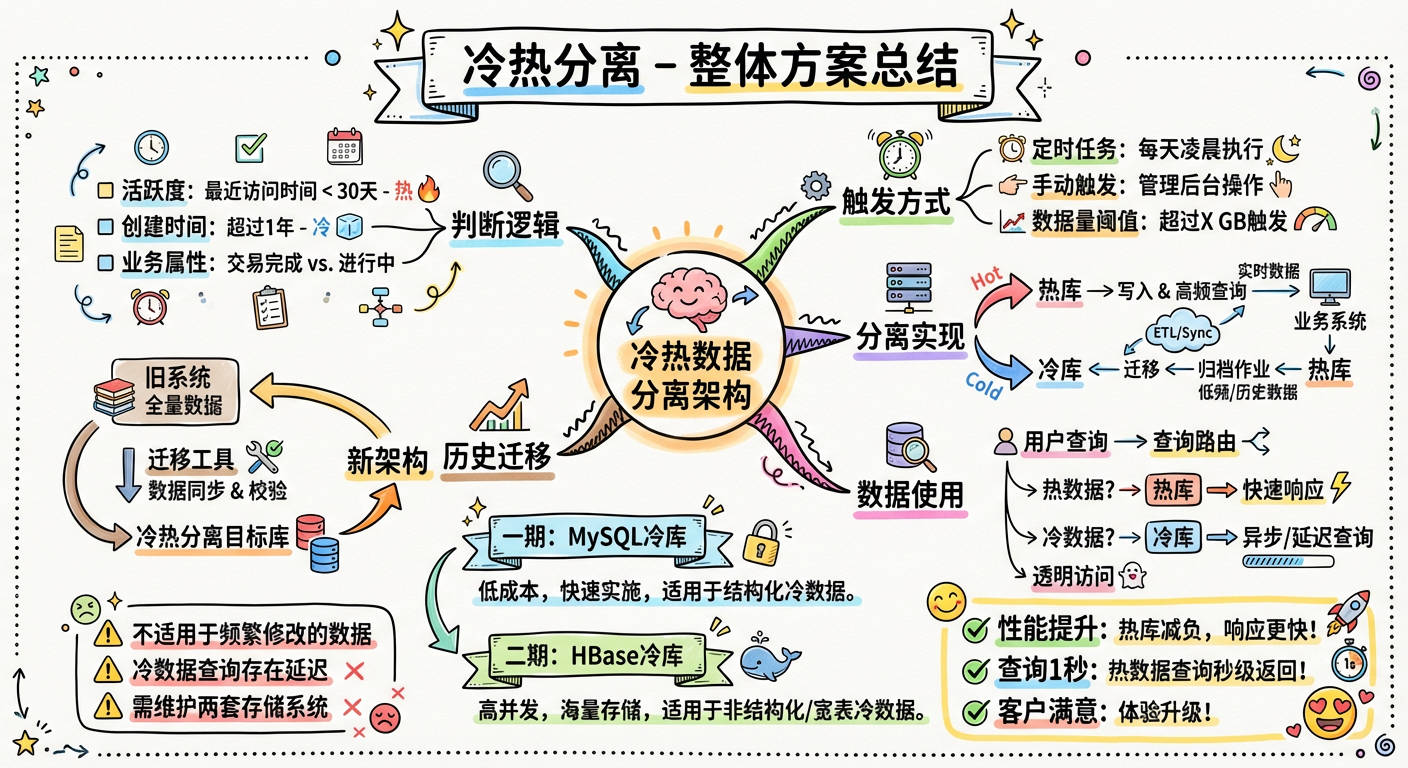
冷热分离方案只是刚好适用于这个场景,它有一些明显的不足。如果碰到下面的任何一个场景,这个方案就不适用了:
- 数据没有"归档"这一特点,经常需要修改
- 所有数据都需要支持复杂的查询,并且需要非常快的响应速度
- 需要实时地对数据进行各种统计
如果碰到以上场景,又该用什么方案来解决?请看下一章:查询分离。