第2章 查询分离
上一场景使用的冷热分离解决方案性价比高,可以快速交付,但它却不是一个最优的方案,仍然存在诸多不足。比如,业务功能上要求不能再修改冷数据,查询冷数据速度慢,无法承受复杂的查询和统计。本章将介绍一个不同的方案——查询分离。
2.1 业务场景:千万工单表如何实现快速查询
本场景中的客服系统承接的是集团的所有业务,每条业务线的客服又分为多个渠道,有电话、在线聊天、微信、微博等。
业务流程是这样的:当客户接线进来以后,不管是通过什么渠道,客服都会登记一个客服工单,而后再根据业务线、工单的类型来登记不同的信息。工单创建后,会按需创建其他的单据,比如退款单、投诉单、充值单等。
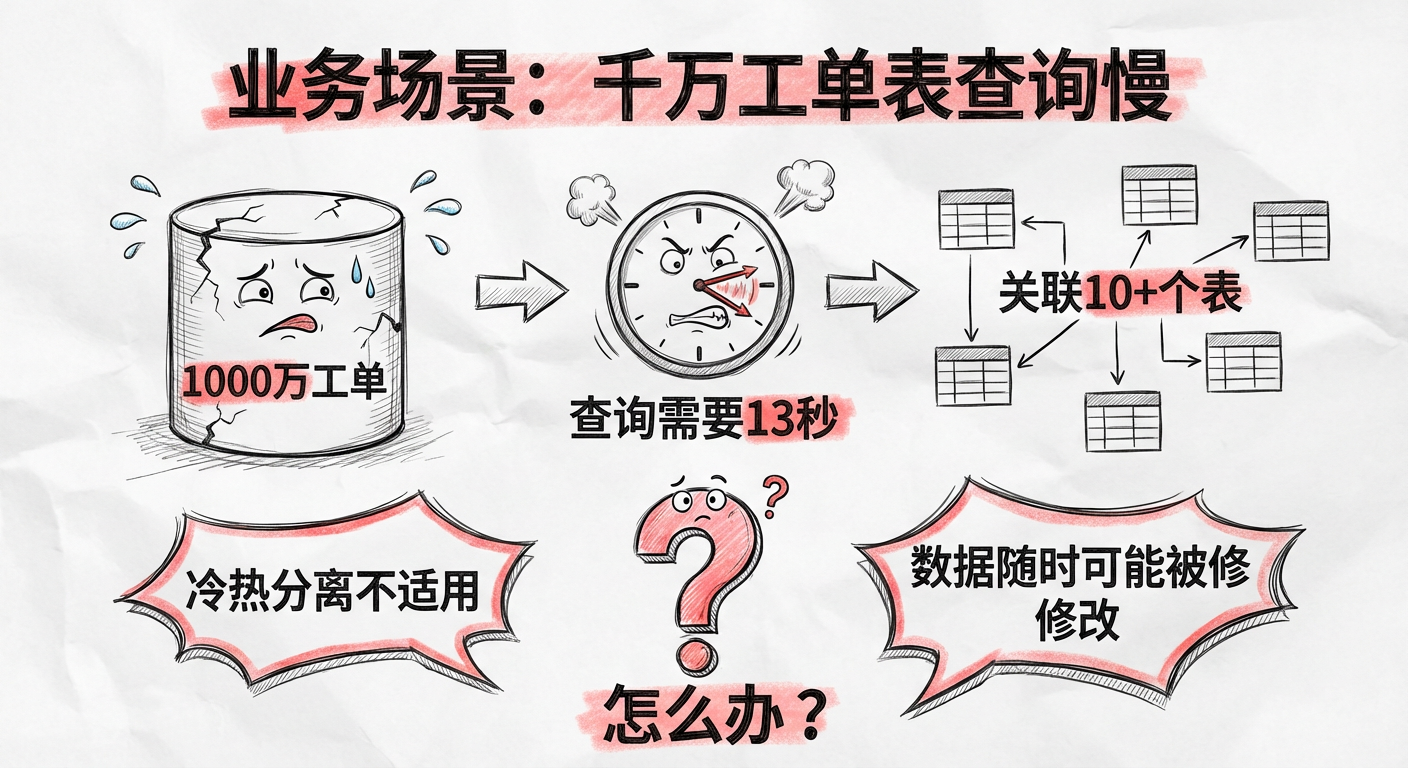
系统已经运作了 5年 左右,已有数据量大,而且随着集团业务的扩大,业务线增加,客服增多,工单数量的增长也越来越快,在系统中查询工单,以及打开工单详情的时候,就会出现响应速度很慢的情况。
项目组调研了查询慢和工单详情打开慢的问题,具体情况如下:
| 问题 | 详情 |
|---|---|
| 查询慢 | 工单数据库里面有 1000万 左右的客服工单,每次查询需要关联近 10个表,一次查询平均花费 13秒 左右 |
| 打开工单慢 | 工单打开后需要调用多个接口,分别将用户信息、订单信息以及其他客服创建的单据信息列出来,打开工单详情页需要近 5秒 |
方案评估过程
项目组最初考虑了几种方案:
-
冷热分离:但这次不适用,因为有些工单的处理涉及诉讼,周期很长(比如 3 年前建的工单最近还在处理)
-
读写分离:MySQL 主从架构,将写操作转入主库,查询操作连接从库。但得到的查询速度提升有限,主要用在数据库高并发场景
-
查询分离(最终方案):将更新的数据放在主数据库里,而查询的数据放在另外一个专门针对搜索的存储系统里
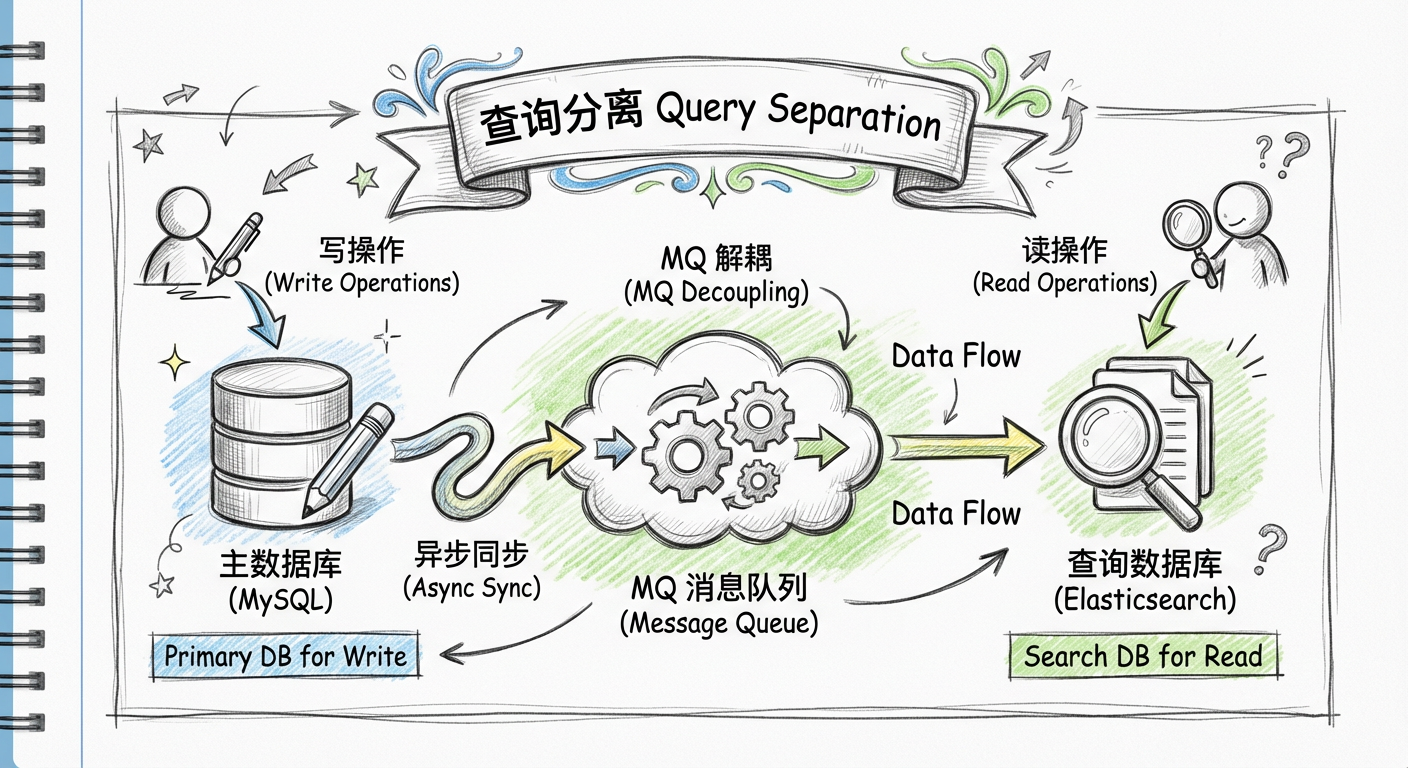
2.2 查询分离简介
2.2.1 何为查询分离
查询分离即每次写数据时保存一份数据到其他的存储系统里,用户查询数据时直接从中获取数据。
对于主数据库,因为数据的更新都是单表更新,不需要关联也没有外键,而且不会被查询操作占用数据库资源,所以写的性能就没有问题了。数据的查询则通过一个专门处理大数据量的查询引擎来解决。
2.2.2 何种场景下使用查询分离
当在实际业务中遇到以下情形时,就可以考虑使用查询分离:
- 数据量大:比如单个表的行数有上千万,当然,如果几百万就出现查询慢的问题,也可以考虑使用
- 查询数据的响应效率很低:因为表数据量大,或者关联查询太过复杂,导致查询很慢的情况
- 所有写数据请求的响应效率尚可:虽然查询慢,但是写操作的响应速度还可以接受的情况
- 所有数据任何时候都可能被修改和查询:这一点是针对冷热分离的,因为如果有些数据走入终态就不再用到,就可以归档到冷数据库了
很多人对查询分离这个概念特别熟悉,但是对于查询分离的使用场景不太理解,这是不够的。只有了解了查询分离的真正使用场景,才能在遇到实际问题时采取最正确的解决方案。
2.3 查询分离实现思路
查询分离的实现需要考虑以下 5 个问题:
- 如何触发查询分离?
- 如何实现查询分离?
- 查询数据如何存储?
- 查询数据如何使用?
- 历史数据如何迁移?
2.3.1 如何触发查询分离
这个问题是说应该在什么时候保存一份数据到查询数据库,即什么时候触发查询分离这个动作。
一般来说,查询分离的触发逻辑分为 3 种:
1. 修改业务代码同步更新查询数据
每次客服单击更新工单的按钮后,在处理该动作的请求线程当中,除了更新工单数据外,还要调用一个更新工单查询数据的操作。直到这些操作都完成以后,再返回请求结果给客服。
2. 修改业务代码异步更新查询数据
客服单击更新工单的按钮后,在处理该动作的请求线程当中,更新工单数据,而后异步发起另外一个线程去更新工单数据到查询数据库。不用等到查询数据更新完成,就直接返回请求结果给客服。
3. 监控数据库日志更新查询数据
监控主数据库的数据库日志文件(binlog),一旦发现有变更,就触发工单数据的更新操作,去更新查询数据。
| 触发方式 | 优点 | 缺点 |
|---|---|---|
| 同步更新 | 业务逻辑灵活可控、实时性强 | 减缓写操作速度 |
| 异步更新 | 业务逻辑灵活可控、不影响写速度 | 用户可能查询到过时数据 |
| 监控 Binlog | 不影响业务代码、不减缓写速度 | 业务逻辑不灵活、用户可能查询到过时数据 |
本项目最终选择了第 2 种方案:修改所有与工单写操作有关的业务代码,在更新完工单数据后,异步触发更新查询数据的逻辑,而后不等查询数据更新完成,就直接返回结果给客服。
2.3.2 如何实现查询分离
项目组选择的是修改业务代码异步更新查询数据。最基本的实现方式是单独启动一个线程来创建查询数据,不过使用这种做法要考虑以下情况:
- 写操作较多且线程太多时,就需要加以控制,否则太多的线程最终会拖垮 JVM
- 创建查询数据的线程出错时,如何自动重试?
- 多线程并发时,很多并发场景需要解决
此时就可以考虑使用 MQ(消息队列) 来解决这些问题。
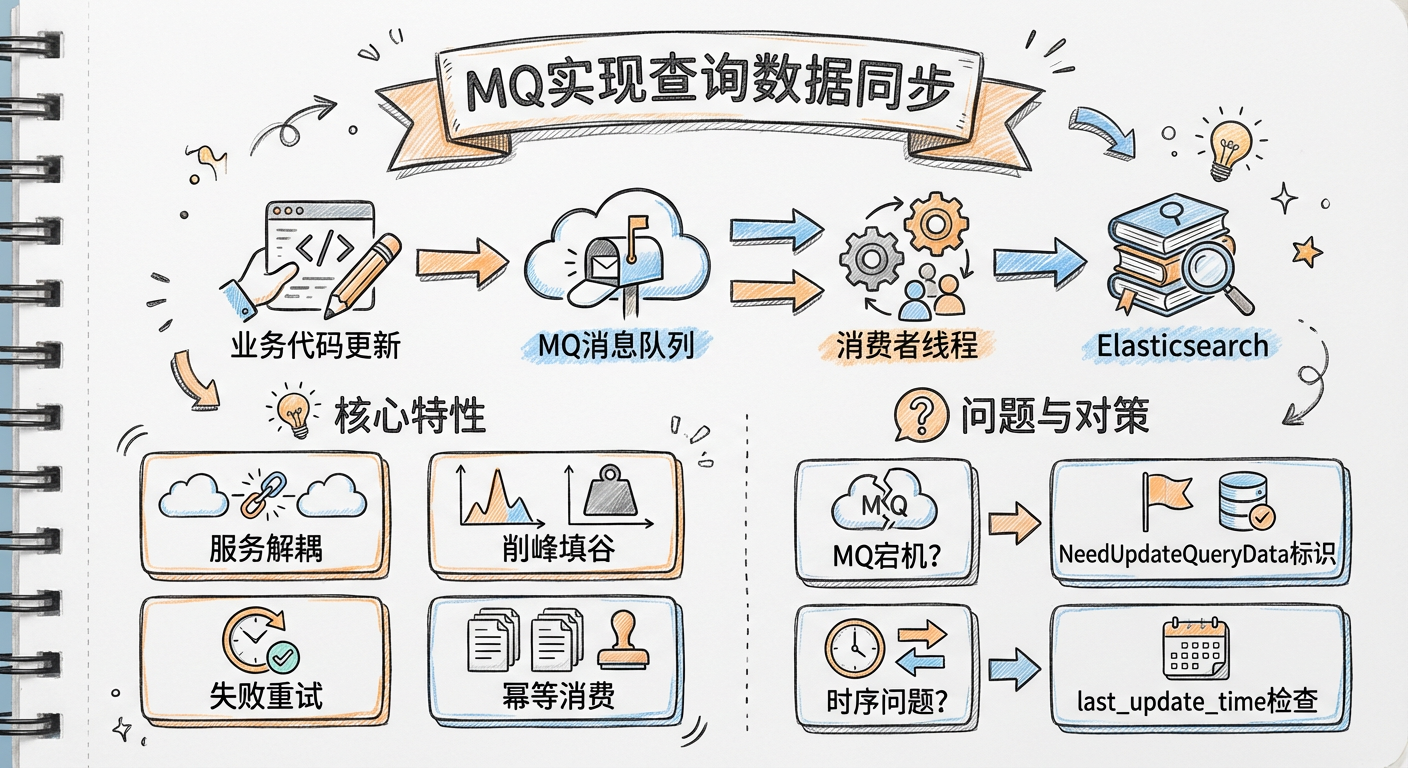
MQ 的具体操作思路
每次程序处理主数据写操作请求时,都会发一个通知给 MQ,MQ 收到通知后唤醒一个线程来更新查询数据。
了解 MQ 的具体操作思路后,还应该考虑以下 5 个问题:
问题1:MQ 如何选型?
如果公司已经使用 MQ,那选型问题也就不存在了。RabbitMQ、RocketMQ、Kafka、ActiveMQ、Redis 都有实际应用。
问题2:MQ 宕机了怎么办?
解决方案分为 3 步:
- 每次进行写操作时,在主数据中加标识
NeedUpdateQueryData=true - MQ 的消费者获取信号后,先批量查询待更新的主数据,然后批量更新查询数据,更新完成后将标识改为
false - 若存在多个消费者同时有迁移动作的情况,需要处理并发性问题
问题3:更新查询数据的线程失败了怎么办?
如果更新的线程失败了,NeedUpdateQueryData 标识就不会更新,后面的消费者会再次将有标识的数据拿出来处理。可以在主数据中添加一个尝试迁移次数,监控那些尝试迁移次数过多的数据。
问题4:消息的幂等消费
需要保证更新查询数据的步骤可以重复执行多次,而且得到的最终结果是一致的。
问题5:消息的时序性问题
如果线程甲启动比乙早,但迁移数据的动作比线程乙还要慢,就有可能导致查询数据最终变成过期的数据。
解决方案:主数据每次更新时,都更新 last_update_time,然后每个线程更新查询数据后,检查当前工单的 last_update_time 是否与线程刚开始获得的时间相同。
- 服务的解耦:主业务逻辑不会依赖更新查询数据这个服务
- 控制并发量:通过控制消息消费者的线程数来控制负载
2.3.3 查询数据如何存储
应该使用什么技术来存储查询数据呢?目前开发者们主要使用 Elasticsearch 实现大数据量的搜索查询,当然还可能用到 MongoDB、HBase 这些技术。
在这个项目中,设计架构方案时选用了 Elasticsearch,原因包括:
- Elasticsearch 对查询的扩展性支持好
- 团队对 Elasticsearch 很熟悉
- 运维人员有 Elasticsearch 的运维经验
2.3.4 查询数据如何使用
数据存到 Elasticsearch 以后,在查询业务代码中直接调用 Elasticsearch 的 API 即可。
不过要考虑一个场景:数据查询更新完前,查询数据不一致怎么办?
两种解决思路:
- 在查询数据更新到最新前,不允许用户查询
- 给用户提示:"您目前查询到的数据可能是 2 秒前的数据,如果发现数据不准确,可以尝试刷新一下。"(推荐)
2.3.5 历史数据迁移
在这个方案里,只需要把所有的历史数据加上标识 NeedUpdateQueryData=true,程序就会自动处理了。
2.3.6 MQ + Elasticsearch 的整体方案
整个方案的要点如下:
- 异步触发:使用异步方式触发查询数据的同步
- MQ 实现异步:通过 MQ 来实现异步效果,同时做到服务解耦和削峰
- Elasticsearch 存储:将工单的查询数据存储在 Elasticsearch 中
- 延时提示:因为查询数据同步到 Elasticsearch 会有一定的延时,需要给用户提示
- 历史数据迁移:通过
NeedUpdateQueryData字段自动批量迁移
2.4 Elasticsearch 注意事项
Elasticsearch 确实是个好工具,但也存在不少陷阱。想掌握好这门技术,除需要对它的用法了如指掌外,还需要对技术中的各种陷阱了然于心。
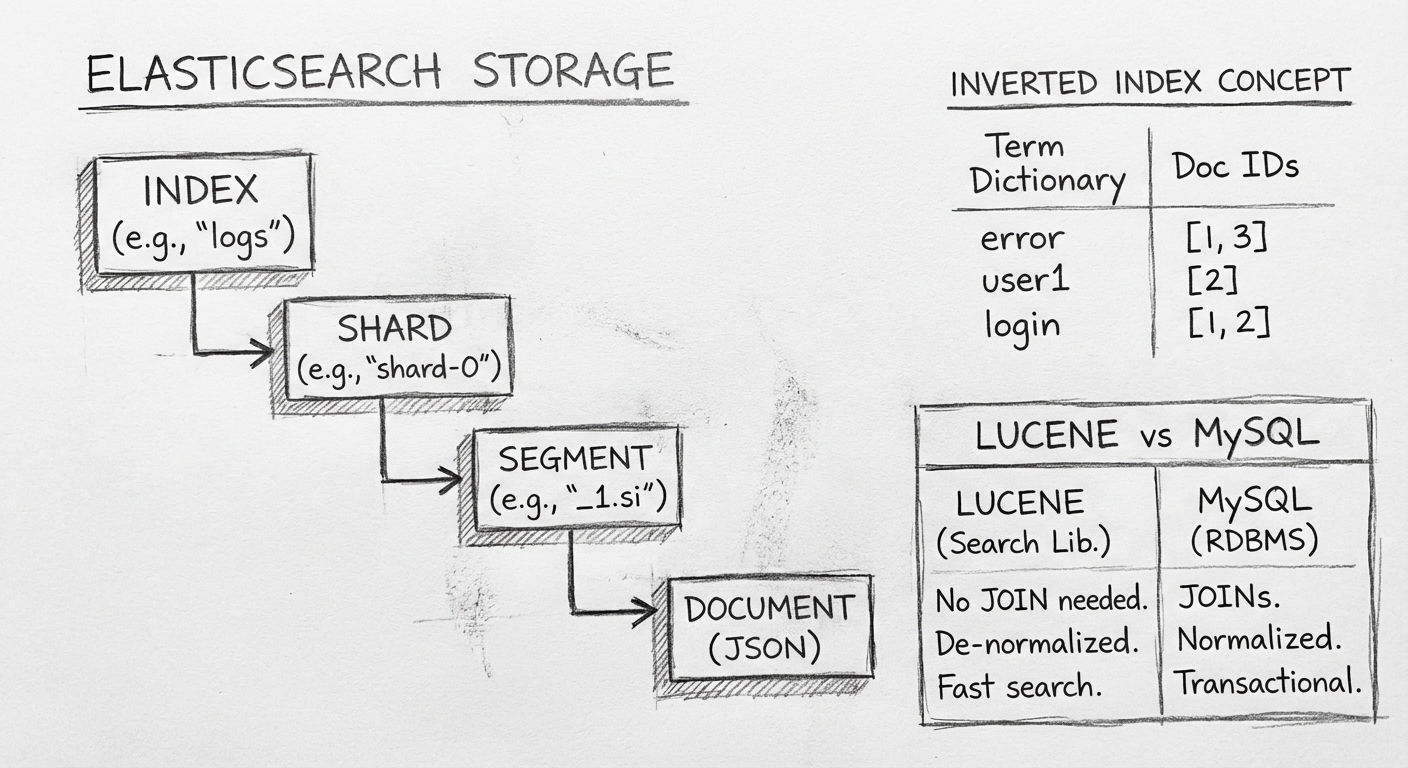
2.4.1 如何使用 Elasticsearch 设计表结构
Elasticsearch 是基于索引的设计,它无法像 MySQL 那样使用 join 查询,所以查询数据时需要把每条主数据及关联子表的数据全部整合在一条记录中。
使用 Elasticsearch 存储数据时并不会设计多个表,而是将所有表的相关字段数据汇集在一个 Document 中,即一个完整的文档结构。
{
"order_id": "12345",
"customer_name": "张三",
"total_amount": 199.00,
"order_items": [
{"product_name": "商品A", "quantity": 2, "price": 99.50},
{"product_name": "商品B", "quantity": 1, "price": 99.50}
]
}
2.4.2 Elasticsearch 的存储结构
Elasticsearch 是一个分布式的查询系统,它的每一个节点都是一个基于 Lucene 的查询引擎。
Lucene 和 MySQL 的概念对比
| Lucene 概念 | MySQL 对应概念 |
|---|---|
| Index(索引) | Database(数据库) |
| Type | Table(表) |
| Document | Row(行) |
| Field | Column(列) |
倒排索引
Lucene 使用的是倒排索引的结构:
- 字典表:存放关键字
- 倒排表:存放该关键字所在的文档 ID
有结构的文档经过倒排索引后,字段中的每个值都是一个关键字,存放在 Term Dictionary(词汇表)中,且每个关键字都有对应地址指向所在文档。
2.4.3 Elasticsearch 如何修改表结构
在实际业务中:
- 增加新字段:Elasticsearch 可以支持直接添加
- 修改字段类型或改名:Elasticsearch 不支持直接修改,因为修改字段的类型会导致索引失效
如果想修改字段的映射,需要:
- 新建一个索引
- 使用 Elasticsearch 的
reindex功能将旧索引复制到新索引中
不建议直接修改 Elasticsearch 的表结构。一般做法是:先保留旧的字段,然后直接添加并使用新的字段,直到新版本的代码全部稳定运行后,再找机会清理旧的不用的字段。
2.4.4 陷阱一:Elasticsearch 是准实时的
当更新数据至 Elasticsearch 且返回成功提示时,会发现通过 Elasticsearch 查询返回的数据仍然不是最新的。
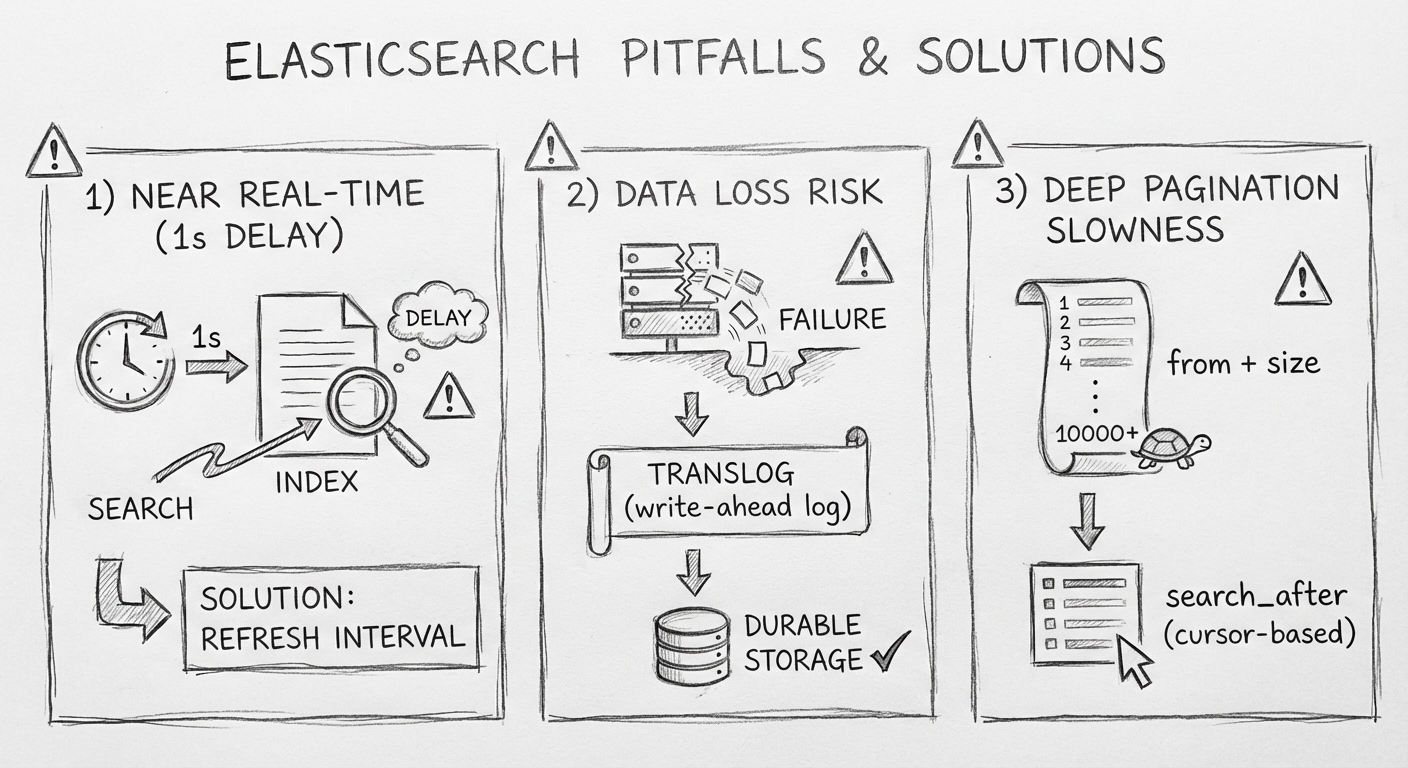
原因分析:
Elasticsearch 的一个 Shard(分片)就是一个 Lucene Index,每一个 Lucene Index 由多个 Segment(段)构成。
数据索引的过程:
- 当新的 Document 被创建时,数据首先会存放到新的 Segment 中
- Shard 收到写请求时,请求会被写入 Translog 中,然后 Document 被存放在 Memory Buffer(内存缓冲区)中
- 每隔 1 秒(默认设置),Refresh 操作被执行一次,Memory Buffer 中的数据会被写入一个 Segment,这时新的数据才可以被搜索到
Elasticsearch 并不是实时的,而是有 1 秒延时。解决方案:提示用户查询的数据会有一定延时即可。
2.4.5 陷阱二:Elasticsearch 宕机恢复后,数据丢失
每隔 1 秒 Memory Buffer 中的数据会被写入 Segment 中,此时这部分数据可被用户搜索到,但没有持久化,一旦系统宕机,数据就会丢失。
解决方案:
- 将
index.translog.durability设置成request:每个请求都会执行 fsync,缺点是耗费资源,性能差一些 - 将
index.translog.durability设置为fsync:每次 Elasticsearch 宕机启动后,先将主数据和 Elasticsearch 数据进行对比,再将缺失的数据找出来
2.4.6 陷阱三:分页越深,查询效率越低
Elasticsearch 的读操作流程分为两个阶段:
- Query Phase:协调节点先把请求分发到所有分片,然后每个分片在本地查询后建一个结果集队列,返回给协调节点进行全局排序
- Fetch Phase:协调节点根据结果集里的 Document ID 向所有分片获取完整的 Document
问题:比如有 5 个分片,需要查询排序序号从 10000 到 10010(from=10000,size=10)的结果,每个分片需要返回 10010 条数据,协调节点需要在内存中计算 10010 × 5 = 50050 条记录。
解决方案:
- 使用
max_result_window配置:默认为 10000,控制用户翻页不能太深 - 使用
search_after功能:适用于确实需要深度翻页的场景,但无法实现跳页
{
"query": { "match_all": {} },
"sort": [{ "total_amount": "desc" }],
"search_after": [10]
}
2.5 小结

查询分离这个解决方案虽然能解决一些问题,但也要认识到它的不足:
-
Elasticsearch 的局限性:有一定延时,深度分页不能自由跳页,会有丢数据的可能性
-
主数据量问题:主数据量越来越大后,写操作还是慢,到时还是会出问题
-
数据一致性:主数据和查询数据不一致时,如果业务逻辑需要查询数据保持一致性,可能无法接受约 2 秒的延时
不能期望一个解决方案既能覆盖所有的问题,还能实现最小的成本损耗。如果碰到一个场景不能接受上面某个或某些不足时,该怎么解决?请看下一章:分表分库。