数据持久化层:思考与改进
概述
本页记录对本部分各章节的思考与改进建议。
第1章 冷热分离 设计改进
原设计问题
(描述原设计存在的问题)
改进方案
(描述你的改进设计)
第2章 查询分离 设计改进
原设计问题
原文档中的查询分离方案存在以下设计缺陷:
1. 消息体设计不合理
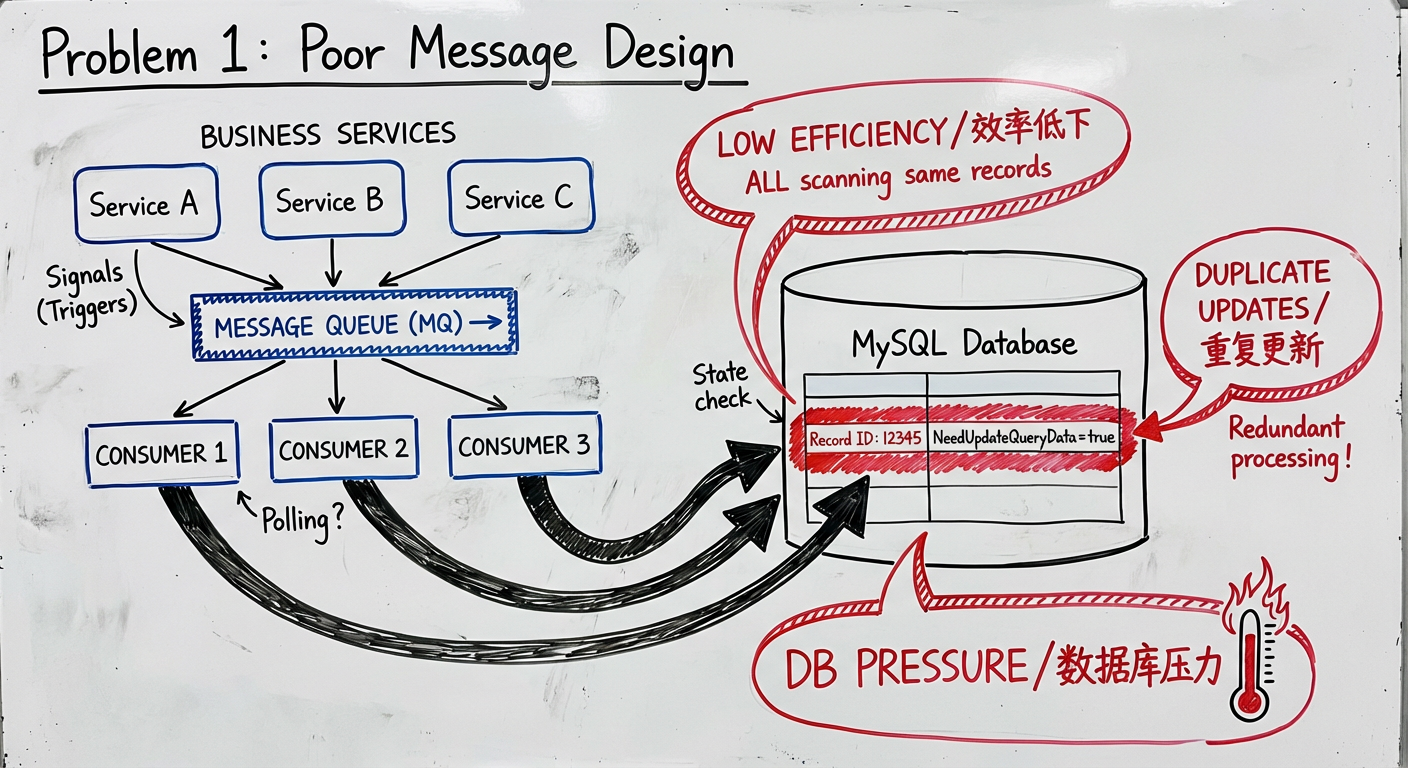
原设计中 MQ 消息仅作为"触发信号",不携带具体业务数据:
"MQ 的消费者获取信号后,先批量查询待更新的主数据,然后批量更新查询数据"
这种设计存在严重问题:
- 效率低下:Consumer 收到消息后需要扫描数据库查找
NeedUpdateQueryData=true的记录,而非直接处理特定记录 - 并发时重复更新:多个业务操作同时触发多个信号,每个 Consumer 都会扫描整个待更新列表,导致同一条记录被多个 Consumer 重复处理,浪费资源
- 延迟增加:额外的数据库扫描步骤增加了同步延迟
- 数据库压力:频繁的批量扫描对数据库造成不必要的负载
- 无法精确追踪:无法知道是哪条记录触发了这次同步,难以监控和排查问题
正确做法:消息体应包含 order_id 和 version,Consumer 可直接定位到具体记录进行处理。
2. 时序性问题解决方案不完善
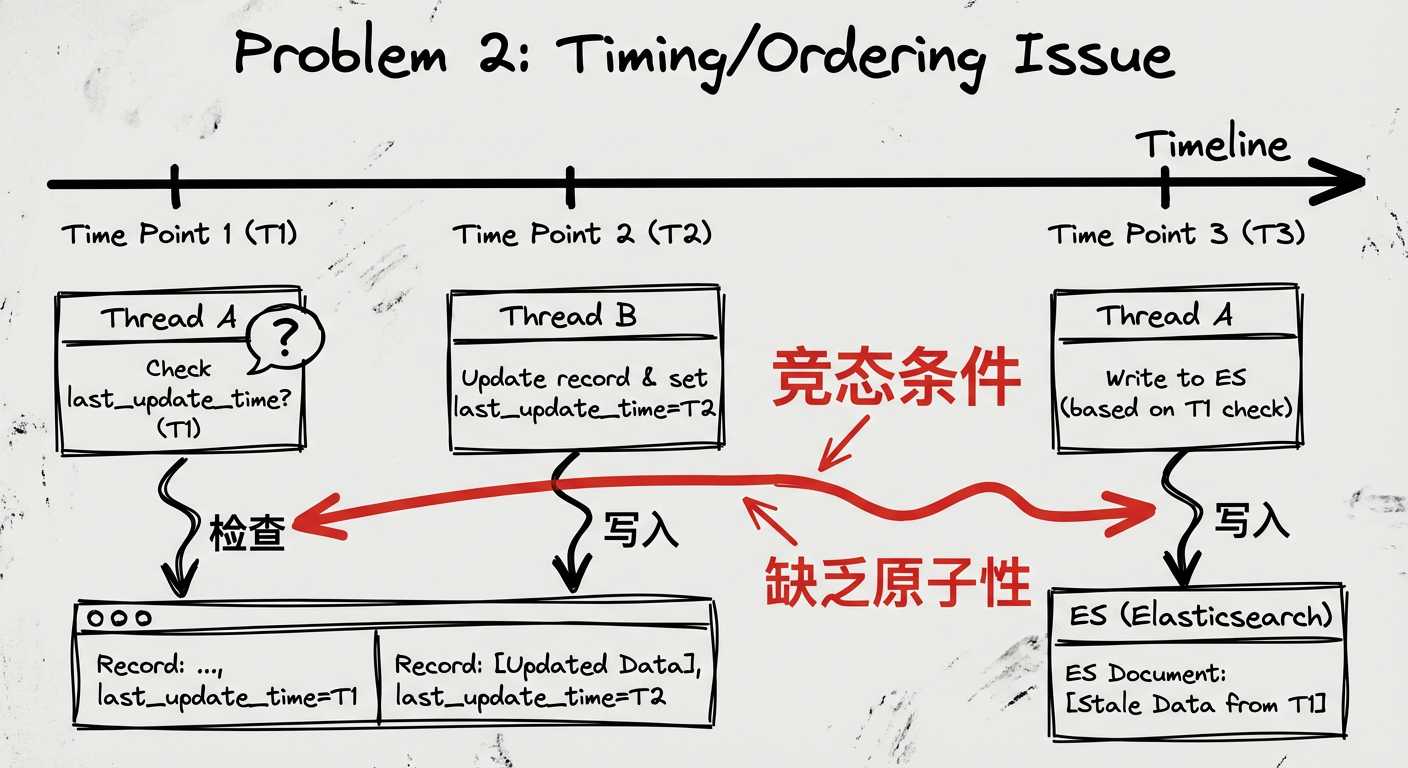
原文提到的解决方案是:在更新查询数据前,检查当前工单的 last_update_time 是否与线程刚开始获得的时间相同。
这个方案存在问题:
- 缺乏原子性:检查和写入不是原子操作,检查通过后、写入前仍可能被其他线程抢先更新,存在竞态条件
- 依赖时间戳:
last_update_time精度有限,高并发下可能出现相同时间戳的情况,无法区分先后顺序
3. 幂等性保证薄弱
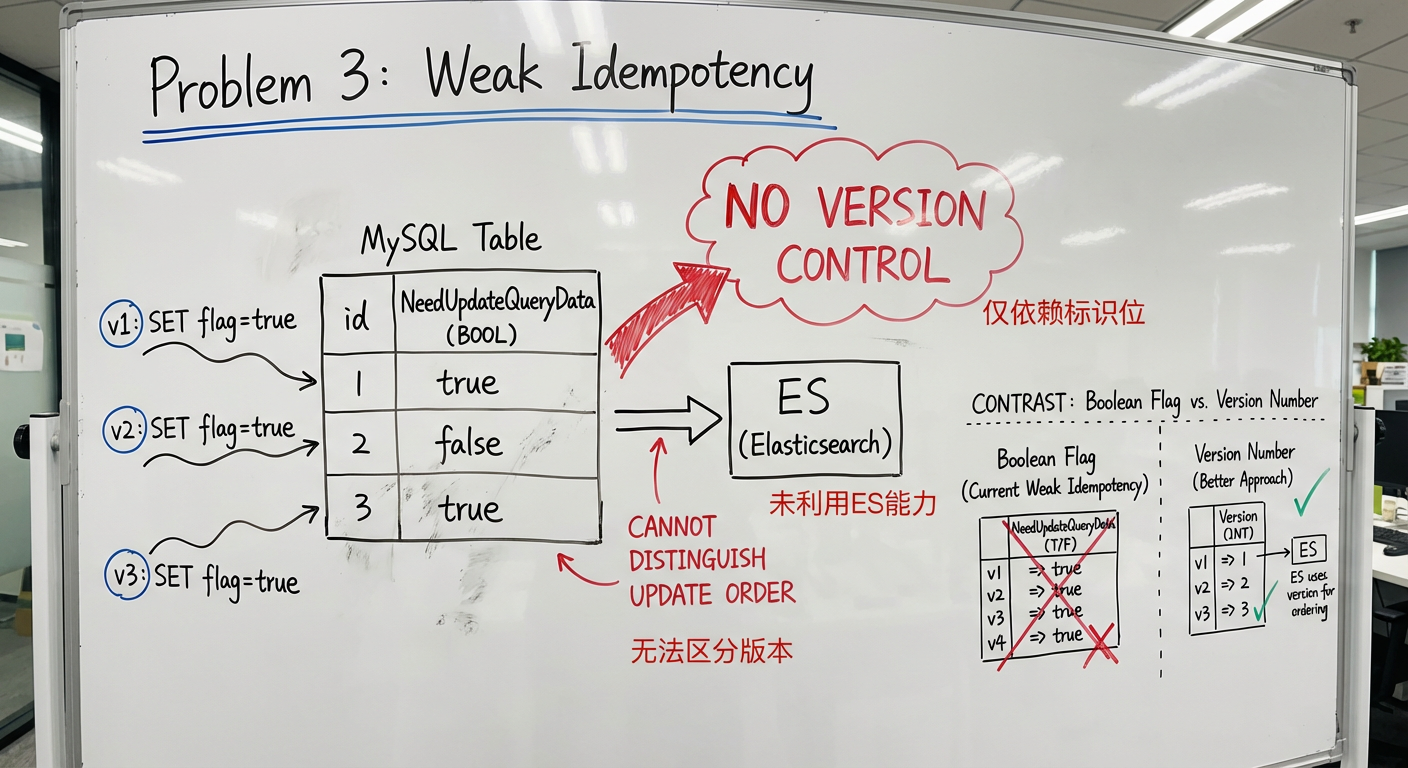
原设计的幂等性设计过于简单:
- 仅依赖标识位:使用
NeedUpdateQueryData布尔标识,无法区分不同版本的更新 - 未利用 ES 能力:Elasticsearch 提供了
version_type=external的乐观锁机制,原设计未加以利用
改进方案
针对上述问题,我们设计了基于版本号的改进方案,通过多层保护机制确保数据一致性和系统可靠性。
改进后的整体架构
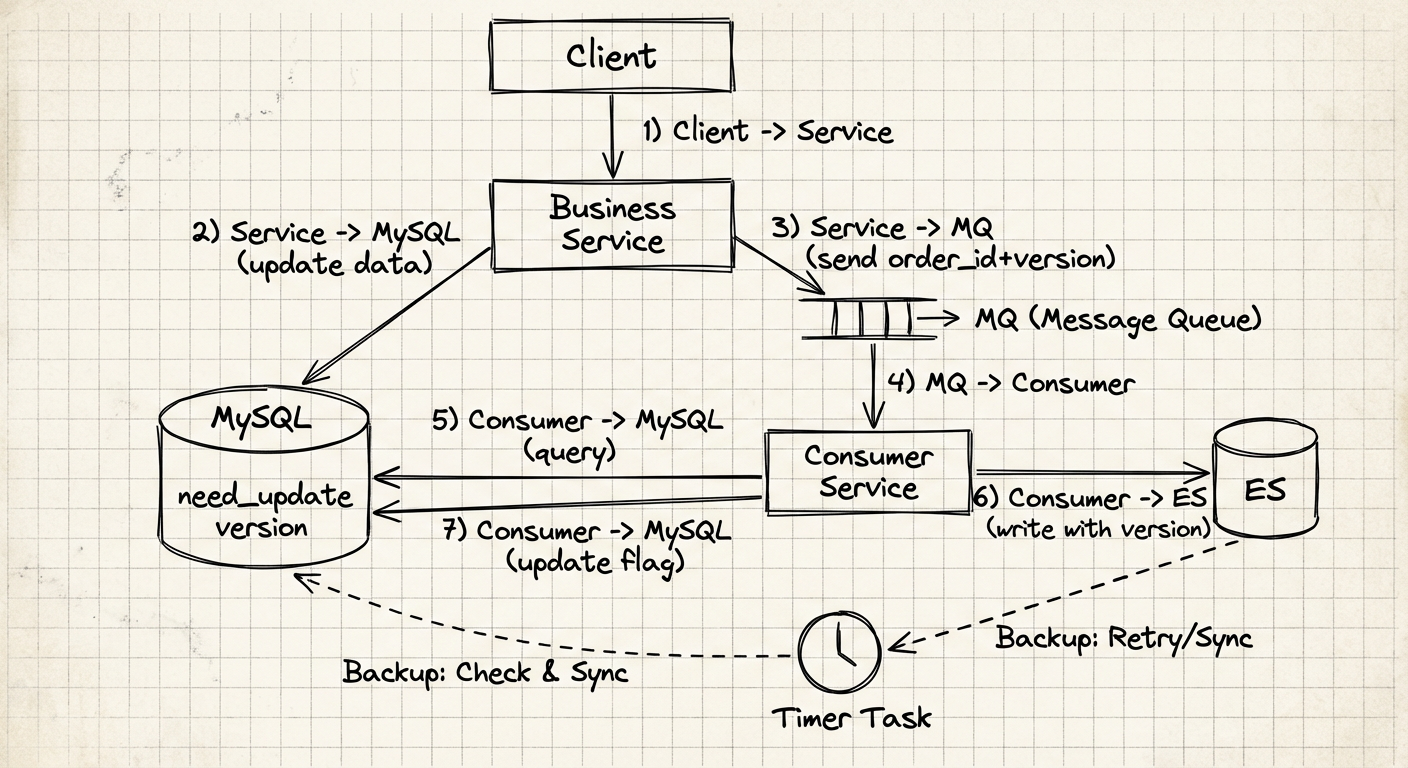
核心改进点:
- 引入版本号机制:MySQL 主表增加
version字段,每次更新时递增 - 版本携带:MQ 消息携带
order_id和version信息 - 版本写入:Consumer 使用
version_type=external写入 ES - 定时兜底:Timer Task 定期扫描
need_update=true的记录进行补偿同步
数据流说明:
1. Client → Service # 客户端请求
2. Service → MySQL (update data) # 更新主数据,version++
3. Service → MQ (send order_id, version) # 发送消息到队列
4. MQ → Consumer # 消费者接收消息
5. Consumer → MySQL (query) # 查询完整数据和当前版本
6. Consumer → ES (write with version) # 带版本写入 ES
7. Consumer → MySQL (update flag) # 更新 need_update=false
消息处理流程
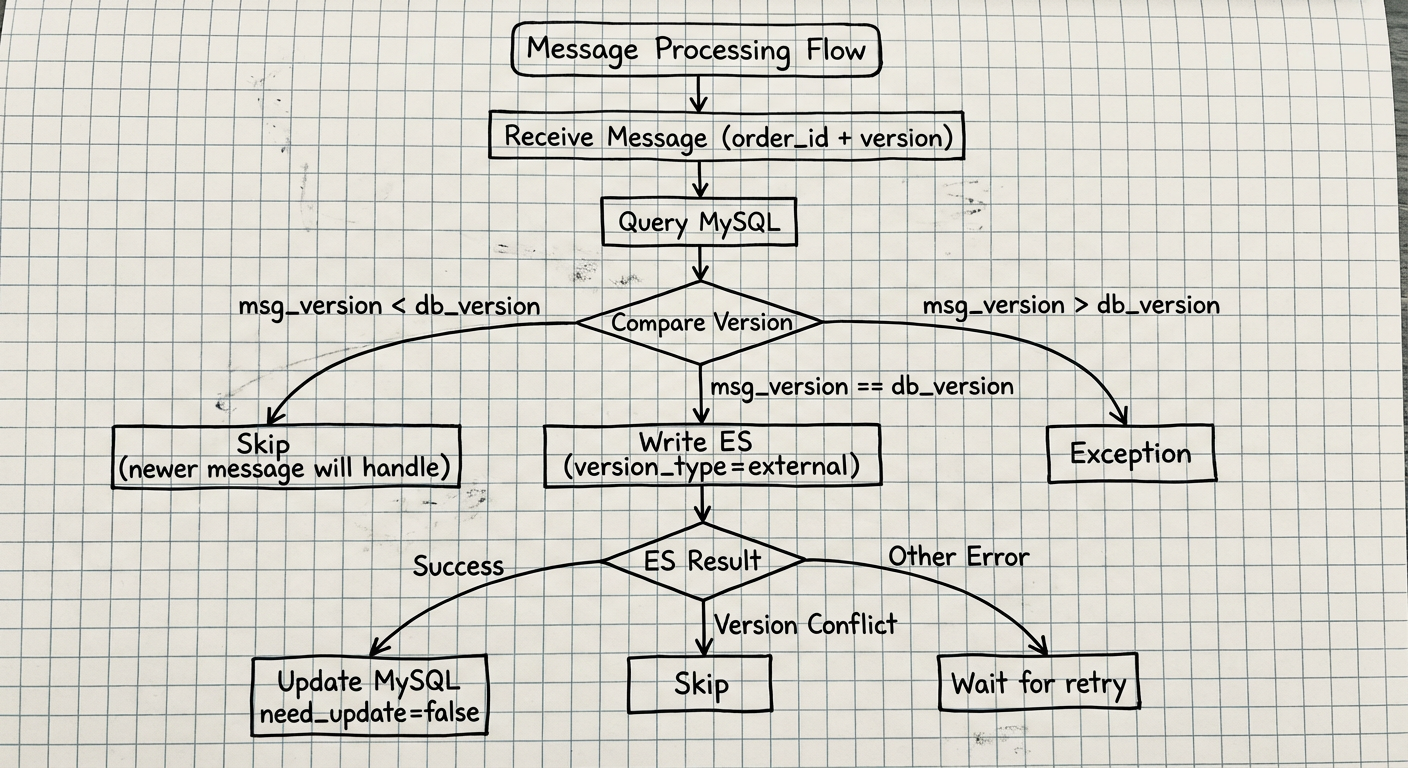
版本比较逻辑:
收到消息 (order_id, msg_version)
↓
查询 MySQL 获取 db_version
↓
比较版本:
├── msg_version < db_version → Skip(已有更新消息会处理)
├── msg_version = db_version → Write ES (version_type=external)
│ ├── Success → Update MySQL need_update=false
│ ├── Version Conflict → Skip(ES 已有更新版本)
│ └── Other Error → Wait for retry
└── msg_version > db_version → Exception(不应发生,需告警)
关键设计:
- 利用 ES 的
version_type=external实现乐观锁 - 版本冲突时直接跳过,因为 ES 中已有更新的数据
- 异常情况记录日志并触发告警
并发场景处理
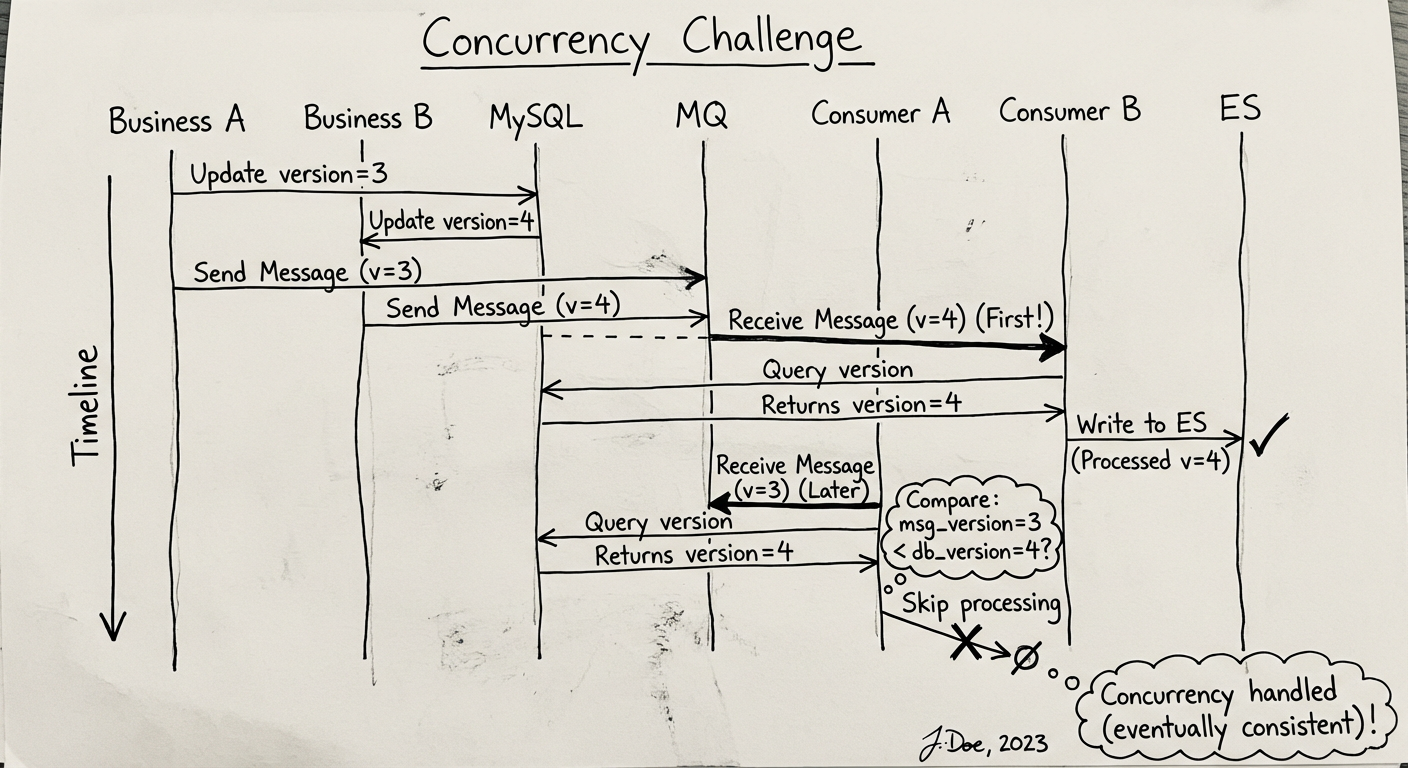
场景说明:
Timeline:
Business A: Update version=3 → Send Message (v=3)
Business B: Update version=4 → Send Message (v=4)
↓
Consumer A 收到 v=4 (先到) Consumer B 收到 v=3 (后到)
↓ ↓
Query: version=4 Query: version=4
↓ ↓
Write ES (v=4) ✓ Compare: 3 < 4 → Skip ✓
结果: 虽然消息乱序到达,但通过版本比较,最终 ES 中保存的是 version=4 的数据,实现最终一致性。
三层幂等性保证
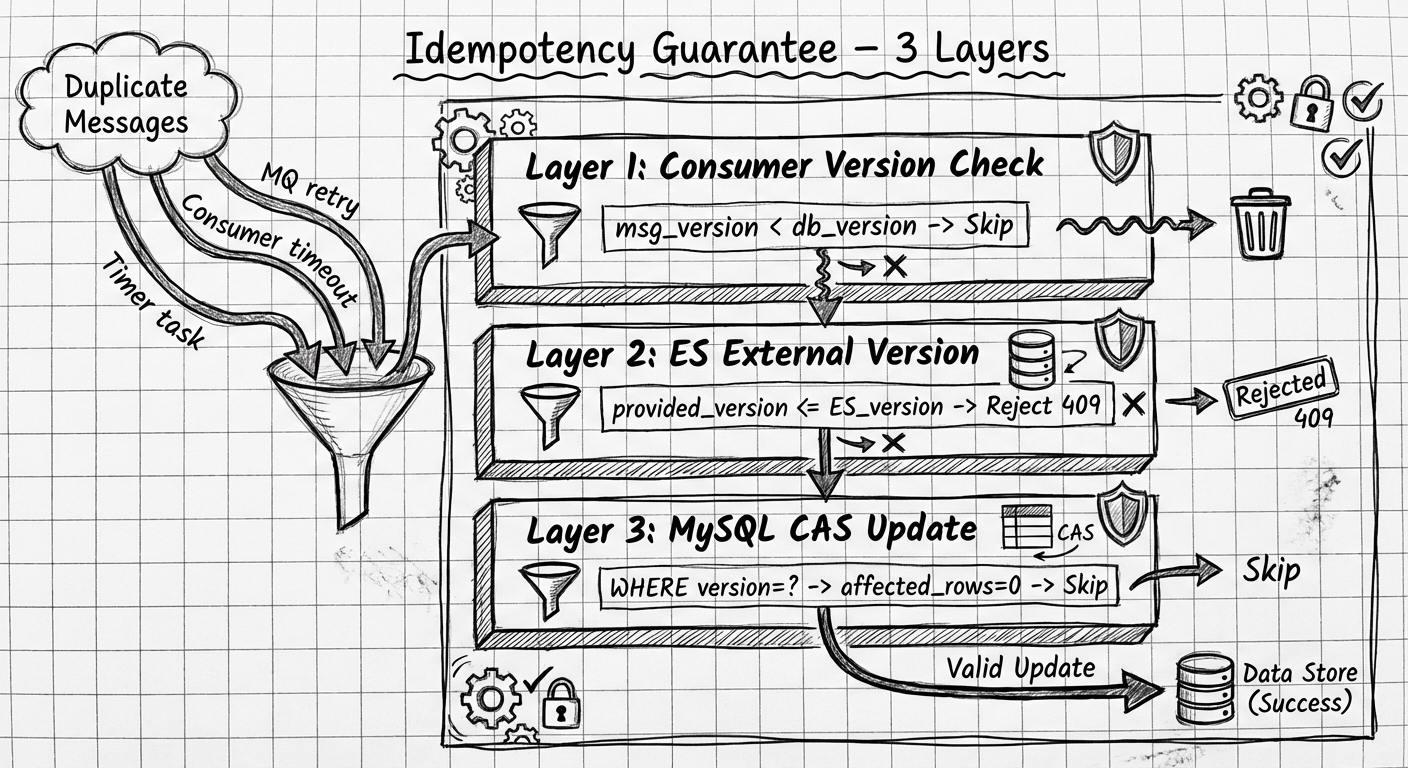
Layer 1: Consumer 版本检查
if msg_version < db_version:
skip # 过时消息,直接跳过
Layer 2: ES External Version
ES 会拒绝 version <= 当前存储版本 的写入
返回 409 Version Conflict → Skip
Layer 3: MySQL CAS 更新
UPDATE orders
SET need_update = false
WHERE order_id = ?
AND version = ?
AND affected_rows > 0
三层保护确保:
- 重复消息不会导致重复处理
- 乱序消息不会覆盖新数据
- 数据库状态更新的原子性
容错与降级机制
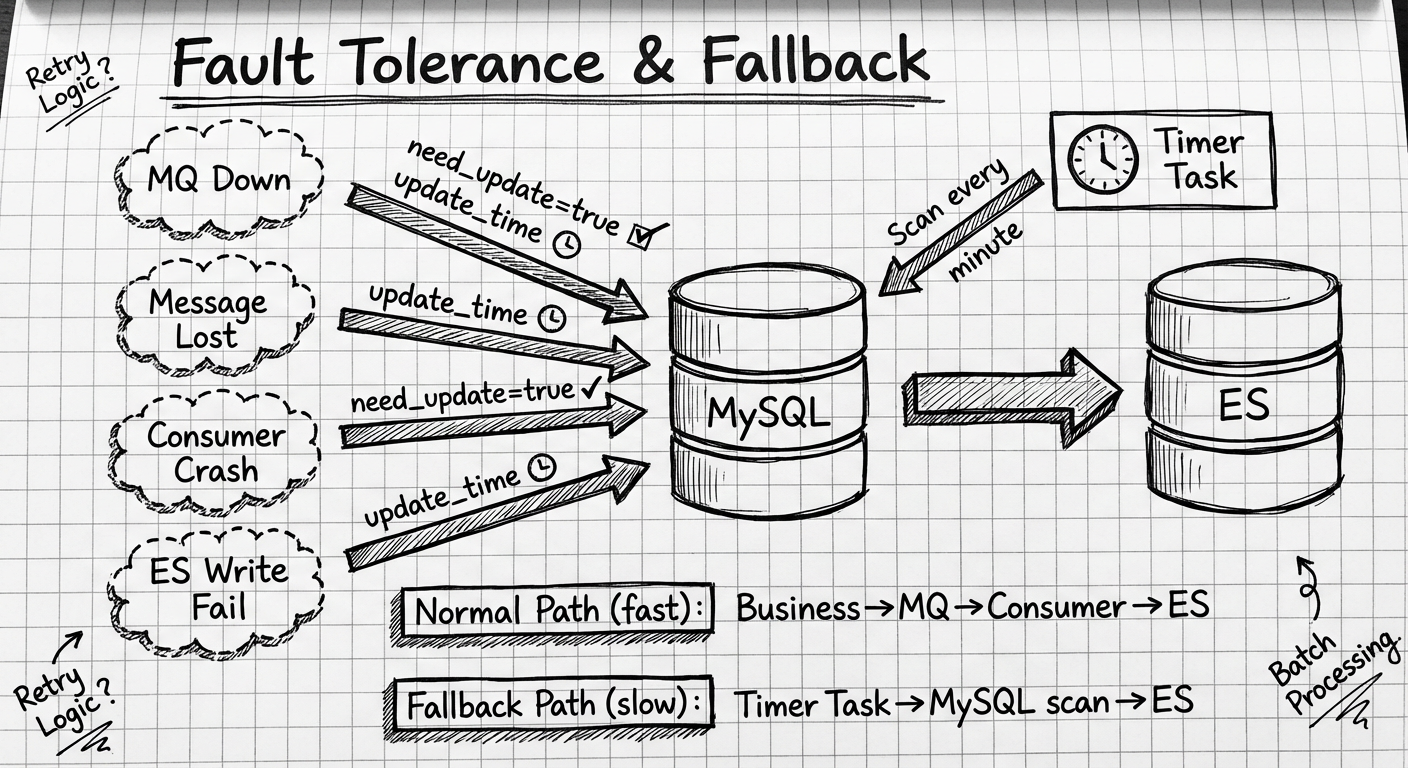
故障场景及处理:
| 故障类型 | 现象 | 处理机制 |
|---|---|---|
| MQ 宕机 | 消息无法发送 | need_update=true 保留,Timer Task 兜底 |
| 消息丢失 | Consumer 未收到 | 同上 |
| Consumer 崩溃 | 处理中断 | need_update=true 未更新,Timer Task 兜底 |
| ES 写入失败 | 返回错误 | 不更新标识,消息重试 / Timer Task 兜底 |
双路径设计:
正常路径(快): Business → MQ → Consumer → ES
降级路径(慢): Timer Task → MySQL scan(need_update=true) → ES
Timer Task 设计要点:
- 定期扫描
need_update=true AND update_time < NOW() - 30s的记录 - 批量处理,控制并发
- 同样遵循版本控制规则
数据一致性分析
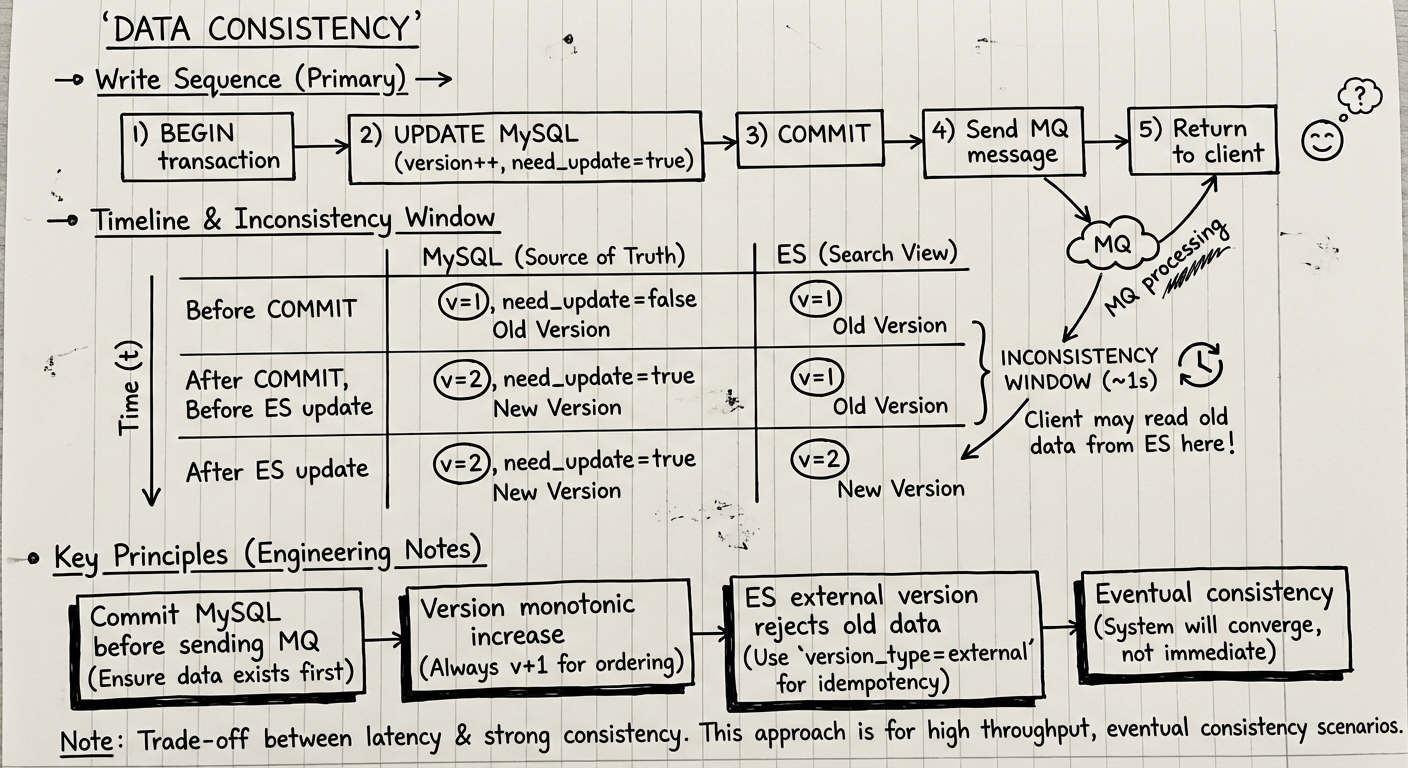
写入时序与不一致窗口:
时间轴:
T0: BEGIN 事务
T1: UPDATE MySQL (need_update=true, version++)
T2: COMMIT 事务
T3: Send MQ 消息
T4: Consumer 处理
T5: ES 更新完成
↓
不一致窗口: [T2, T5]
各时间点数据状态:
| 时间点 | MySQL (Source of Truth) | ES (Search View) | 说明 |
|---|---|---|---|
| T1 (COMMIT前) | Old Version | Old Version | 事务未提交 |
| T2 (COMMIT后) | New Version, need_update=true | Old Version | 不一致开始 |
| T5 (ES更新后) | New Version, need_update=false | New Version | 一致性恢复 |
关键工程原则:
-
提交前设置标识:确保数据存在即有标识,不会遗漏
BEGIN;
UPDATE orders SET ..., need_update=true, version=version+1;
COMMIT;
-- 然后发 MQ -
版本单调递增:永不回退,拒绝旧版本写入
-
最终一致性保证:
- 正常路径:毫秒级延迟
- 降级路径:Timer Task 周期(如 30 秒)
- 客户端可显示:"数据同步中,如有不一致请稍后刷新"
改进前后对比
| 维度 | 原设计 | 改进设计 |
|---|---|---|
| 消息体设计 | 仅触发信号,需扫描数据库 | 携带 order_id + version,直接定位处理 |
| 时序性保证 | 检查 last_update_time,缺乏原子性 | 版本号 + ES external version,原子性保证 |
| 幂等性保证 | 单层(标识位) | 三层(Consumer + ES + MySQL CAS) |
第3章 分表分库 设计改进
原设计问题
(描述原设计存在的问题)
改进方案
(描述你的改进设计)