第4章 读缓存
第1部分已经讲解了数据持久化层相关的架构方案,本章开始正式进入第2部分——缓存层场景实战。这一章主要围绕数据库读取操作频繁的问题进行探讨。
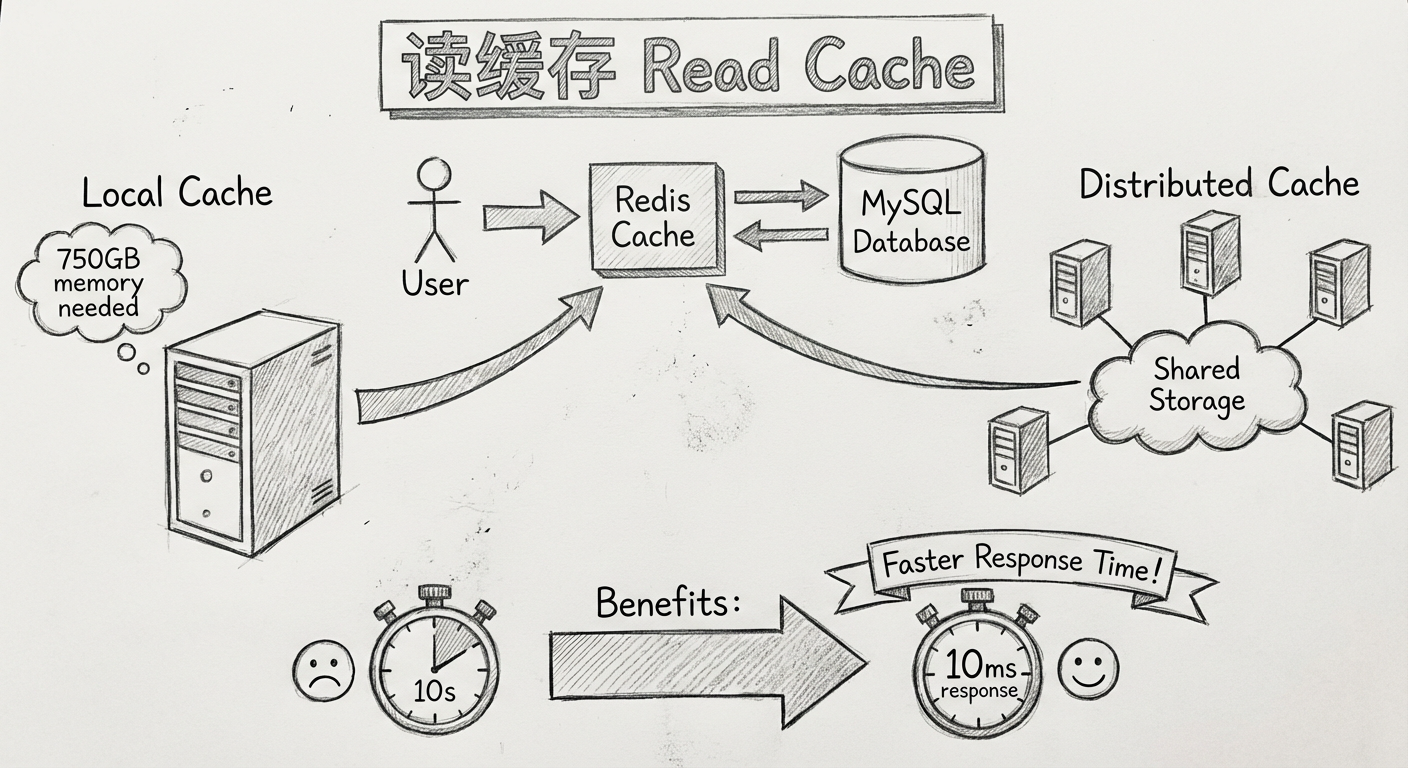
4.1 业务场景:如何将十几秒的查询请求优化成毫秒级
这次项目针对的系统是一个电商系统。每个电商系统都有个商品详情页。一开始这个页面很简单,只包括商品的图片、介绍、规格、评价等。
刚开始,这个页面打开很快,系统运行平稳可靠。后来,页面中陆续加入了:
- 商品推荐(显示推荐商品列表)
- 最近成交情况(显示某人在什么时候下单)
- 优惠活动(显示商品可参加的活动)
- ……
当时这个系统里面有 5万多 条商品数据,数据量并不大,但是每次用户浏览商品详情页时都需要几十条 SQL 语句,经常出现 十几秒 才能打开详情页的情况。
公司有个第三方监控工具,从国内各地监控系统几个关键路径的性能。其中一个关键路径是从首页到搜索再到商品详情页的时长,这个平均时长从刚开始的 3.61秒 逐渐变成后来的 15.53秒。
解决思路
重构数据库基本不可能,最好不要改动表结构。大家想到的方案很通用:把大部分商品的详情数据缓存起来,少部分的数据通过异步加载。
关于缓存,最简单的实现方法就是使用本地缓存,即把商品详情数据放在 JVM 里面。但通过简单换算后发现这个方法明显不合理:
| 计算项 | 数据 |
|---|---|
| 单条商品数据大小 | 约 500KB |
| 商品数量 | 50000条 |
| 所需内存 | 500KB × 50000 ≈ 25GB |
| 服务器节点数 | 30个 |
| 总内存需求 | 750GB |
为此,项目组决定使用另外一个解决办法——分布式缓存,先将所有的缓存数据集中存储在同一个地方,而非重复保存到各个服务器节点中,然后所有的服务器节点都从这个地方读取数据。
4.2 缓存中间件技术选型
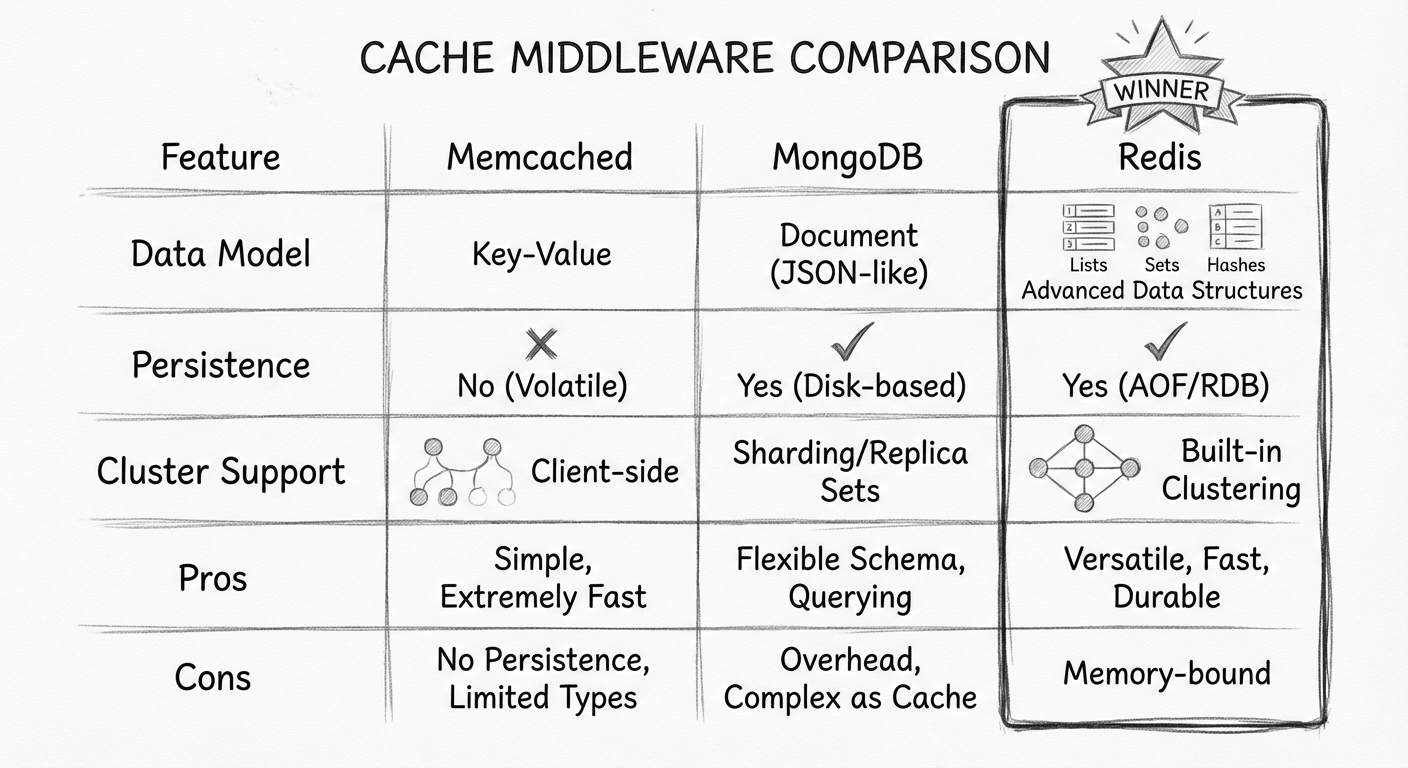
先将目前比较流行的缓存中间件 Memcached、MongoDB、Redis 进行简单对比:
| 特性 | Memcached | MongoDB | Redis |
|---|---|---|---|
| 定位 | 纯内存缓存 | 文档数据库 | 内存数据结构存储 |
| 数据结构 | 简单Key-Value | 文档型 | 丰富的数据结构 |
| 持久化 | 不支持(1.5.18后有限支持) | 支持 | 支持 |
| 集群 | 客户端分片 | 原生支持 | 原生支持 |
目前,Redis 比 Memcached 更流行,主要原因有 3 点:
1. 数据结构
在使用 Memcached 保存 List 缓存对象的过程中,如果往 List 中增加一条数据:
- Memcached:需要读取整个 List → 反序列化塞入数据 → 再序列化存储回去
- Redis:仅需一个请求,直接帮助塞入数据并存储
2. 持久化
- Memcached:一旦系统宕机数据就会丢失(设计初衷就是纯内存缓存)
- Redis:有持久化功能
3. 集群
- Memcached:集群设计简单,客户端根据 Hash 值直接判断存取节点
- Redis:集群在高可用、主从、冗余、Failover 等方面都有所考虑,属于较常规的分布式高可用架构
因此,项目组最终决定使用 Redis 作为缓存的中间件。
4.3 缓存何时存储数据
使用缓存的逻辑如下:
- 先尝试从缓存中读取数据
- 若缓存中没有数据或者数据过期,再从数据库中读取数据保存到缓存中
- 最终把缓存数据返回给调用方
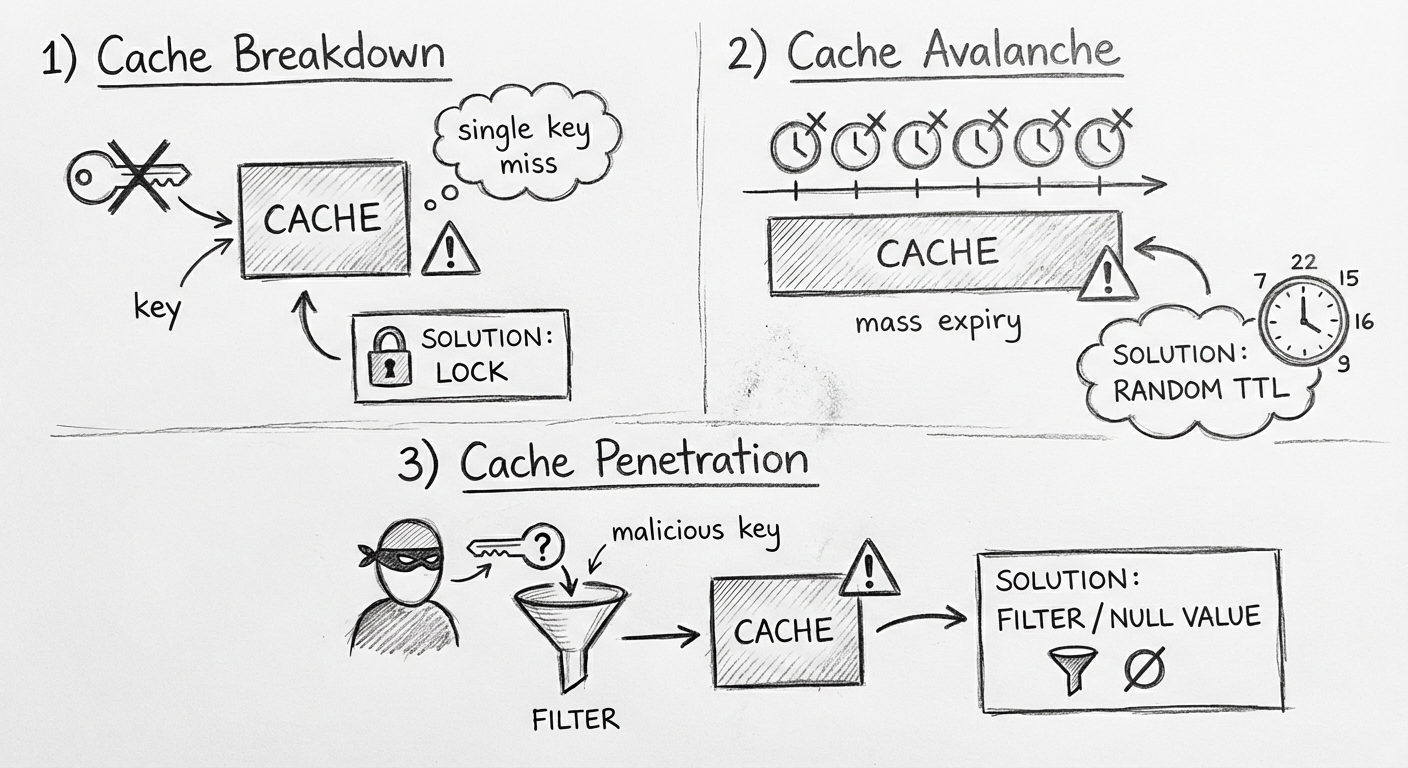
这种逻辑唯一麻烦的地方是,当用户发来大量的并发请求时,它们会发现缓存中没有数据,那么所有请求会同时挤在第2步,此时如果这些请求全部从数据库读取数据,就会让数据库崩溃。
数据库崩溃的3种情况
1. 缓存击穿
定义:单一数据过期或者不存在
解决方案:第一个线程如果发现 Key 不存在,就先给 Key 加锁,再从数据库读取数据保存到缓存中,最后释放锁。如果其他线程正在读取同一个 Key 值,那么必须等到锁释放后才行。
2. 缓存雪崩
定义:数据大面积过期或者 Redis 宕机
解决方案:设置缓存的过期时间为随机分布或设置永不过期即可。
3. 缓存穿透
定义:一个恶意请求获取的 Key 不在数据库中
比如正常的商品 ID 是从 100000 到 1000000,那么恶意请求就可能会故意请求 2000000 以上的数据。这种情况如果不做处理,恶意请求每次进来时,肯定会发现缓存中没有值,那么每次都会查询数据库。
解决方案:
- 在业务逻辑中直接校验,在数据库不被访问的前提下过滤掉不存在的 Key
- 针对恶意请求的 Key 存放一个空值在缓存中,防止恶意请求骚扰数据库
缓存预热
最理想的情况是在用户请求过来之前把数据都缓存到 Redis 中。这就是缓存预热。
具体做法就是在深夜无人访问或访问量小的时候,将预热的数据保存到缓存中,这样流量大的时候,用户查询就无须再从数据库读取数据了。
4.4 如何更新缓存
更新缓存的步骤特别简单,共两步:更新数据库和更新缓存。但这简单的两步中需要考虑很多问题:
- 先更新数据库还是先更新缓存?更新缓存时先删除还是直接更新?
- 假设第一步成功了,第二步失败了怎么办?
- 假设两个线程同时更新同一个数据,A线程先完成第一步,B线程先完成第二步怎么办?
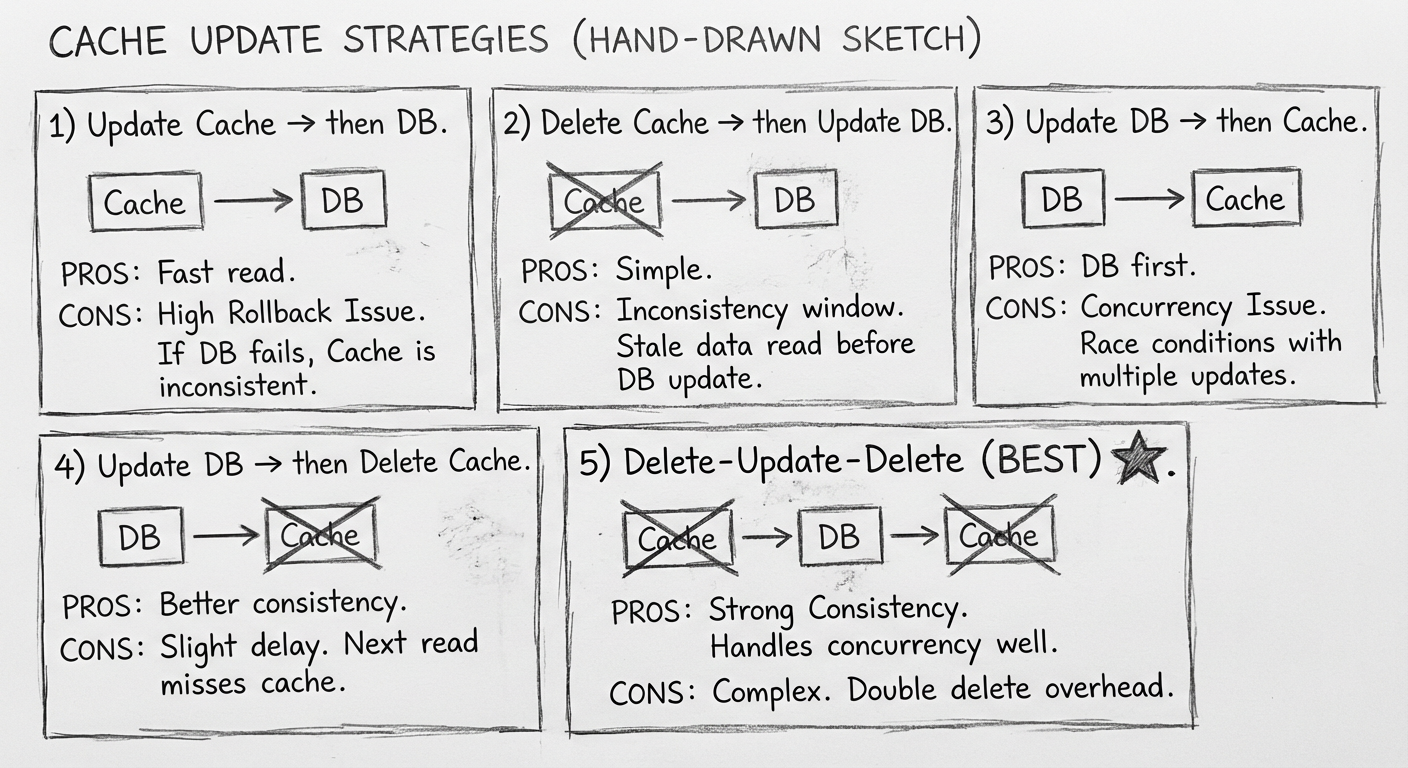
4.4.1 组合1:先更新缓存,再更新数据库
问题:假设第二步更新数据库失败了,要求回滚缓存的更新,这时该怎么办呢?
Redis 不支持事务回滚,除非采用手工回滚的方式。这种解决方案有缺陷,需要考虑事务隔离级别的一些逻辑,成本太大。不推荐。
4.4.2 组合2:先删除缓存,再更新数据库
问题:
- 线程 A 删除缓存后,线程 B 可能将旧值重新存入缓存,导致数据不一致
- 为解决一致性问题加锁,会导致大量读请求卡住
典型的高可用和一致性难以两全的问题。不推荐。
4.4.3 组合3:先更新数据库,再更新缓存
问题:
- 第二步失败需要重试,重试延时会导致数据不一致
- 两个线程并发更新时,可能出现缓存值与数据库值不一致
不推荐。
4.4.4 组合4:先更新数据库,再删除缓存
- 解决了组合3的第二个问题(删除比更新简单,不会出现值不一致)
- 出现问题的概率较低
小缺陷:线程 A 更新数据库后、删除缓存前,线程 B 读取的是旧数据。
4.4.5 组合5:先删除缓存,更新数据库,再删除缓存(推荐)
这个方案出现问题的概率更低,因为要刚好有3个线程配合才会出现问题。
相比于组合4,组合5规避了第二步删除缓存失败的问题——组合5是先删除缓存,再更新数据库,假设它的第三步"再删除缓存"失败了,也没关系,因为缓存已经删除了。
需要考虑的问题:
- 删除缓存数据后变相出现缓存击穿 → 前面已给出方案
- 删除缓存失败如何重试 → 简单同步重试一次即可
- 不可避免的脏数据问题 → 概率已大大降低,需与业务沟通
任何一个方案都不是完美的,但如果剩下 1% 的问题需要花好几倍的代价去解决,从技术上来讲得不偿失,这就要求架构师去说服业务方,去平衡技术的成本和收益。
4.5 缓存的高可用设计
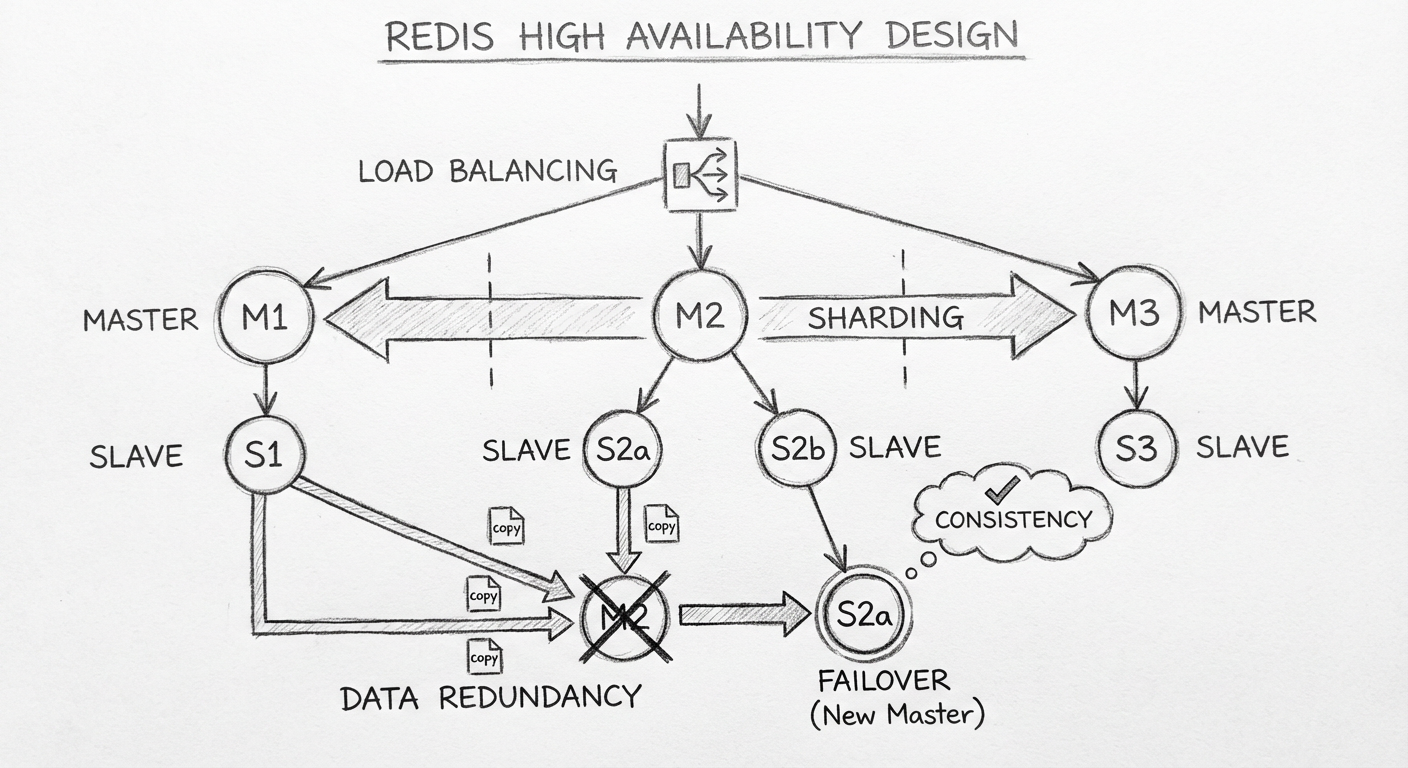
设计高可用方案时,需要考虑 5 个要点:
| 要点 | 说明 |
|---|---|
| 负载均衡 | 是否可以通过加节点的方式来水平分担读请求压力 |
| 分片 | 是否可以通过划分到不同节点的方式来水平分担写压力 |
| 数据冗余 | 一个节点的数据如果失效,其他节点的数据是否可以直接承担失效节点的职责 |
| Failover | 任何节点失效后,集群的职责是否可以重新分配以保障集群正常工作 |
| 一致性保证 | 在数据冗余、Failover、分片机制的数据转移过程中,能否保证数据的一致性 |
如果对缓存高可用有需求,可以使用 Redis 的 Cluster 模式,以上 5 个要点它都会涉及。
4.6 缓存的监控
缓存上线以后,还需要定时查看其使用情况,再判断业务逻辑是否需要优化。
一般会监控的指标:
- 缓存命中率
- 内存利用率
- 慢日志
- 延迟
- 客户端连接数
目前也有很多开源的监控工具,如 RedisLive、Redis-monitor。
4.7 小结
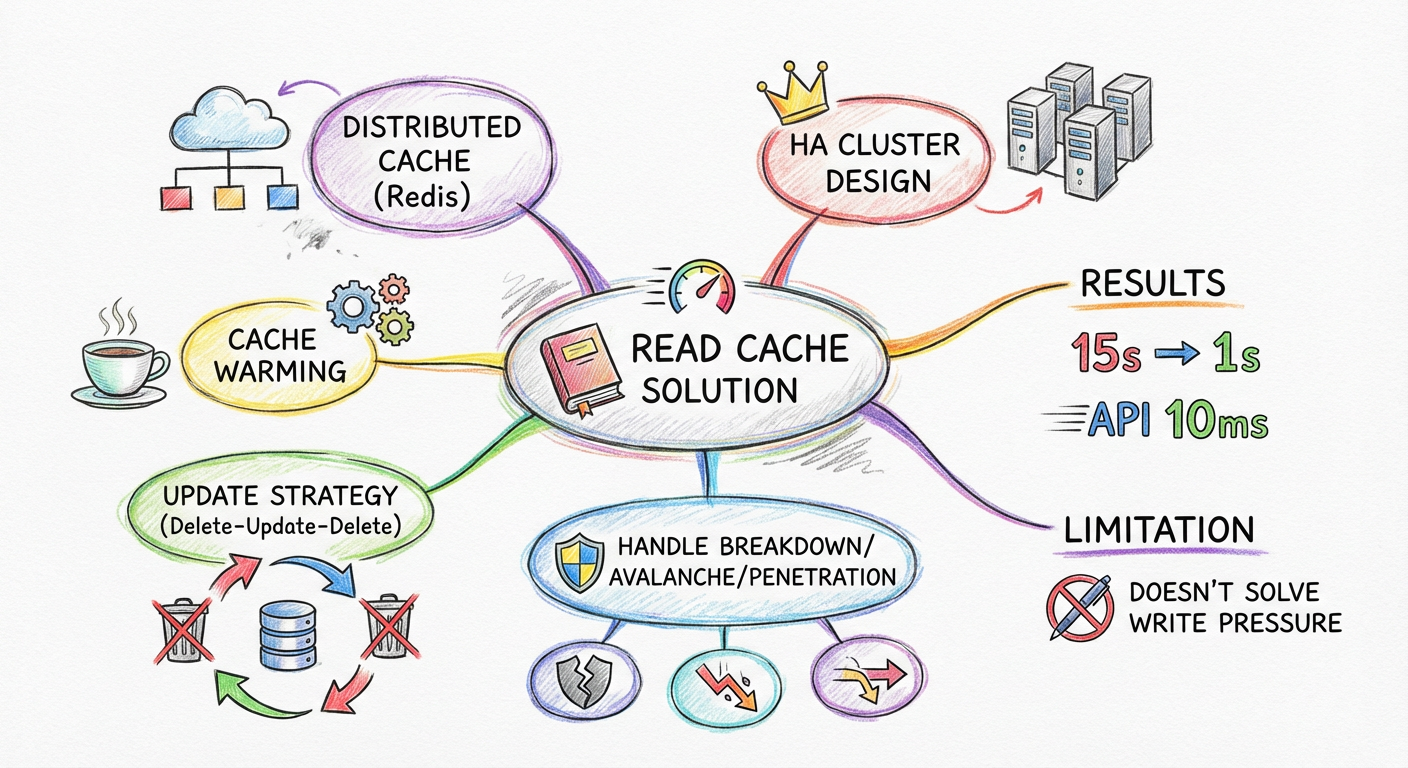
以上方案可以顺利解决读数据请求压垮数据库的问题,目前互联网架构也基本是采取这个方案。
分布式缓存系统上线后的优化效果:
| 指标 | 优化前 | 优化后 |
|---|---|---|
| 详情页打开时间 | 十几秒 | 约1秒 |
| 详情页API响应时长 | - | 10毫秒以内 |
| 首页到详情页平均时长 | 15.53秒 | 约4秒 |
方案不足
这个方案主要针对读数据请求量大的情况,或者读数据响应时间很长的情况,而不能应对写数据请求量大的场景。也就是说写请求多时,数据库还是会支撑不住。
针对这个问题,下一章会给出对应的解决方案:写缓存。