第9章 全链路日志
第8章介绍了服务的注册发现,这里就来谈谈所有微服务都会遇到的一个问题——全链路日志。
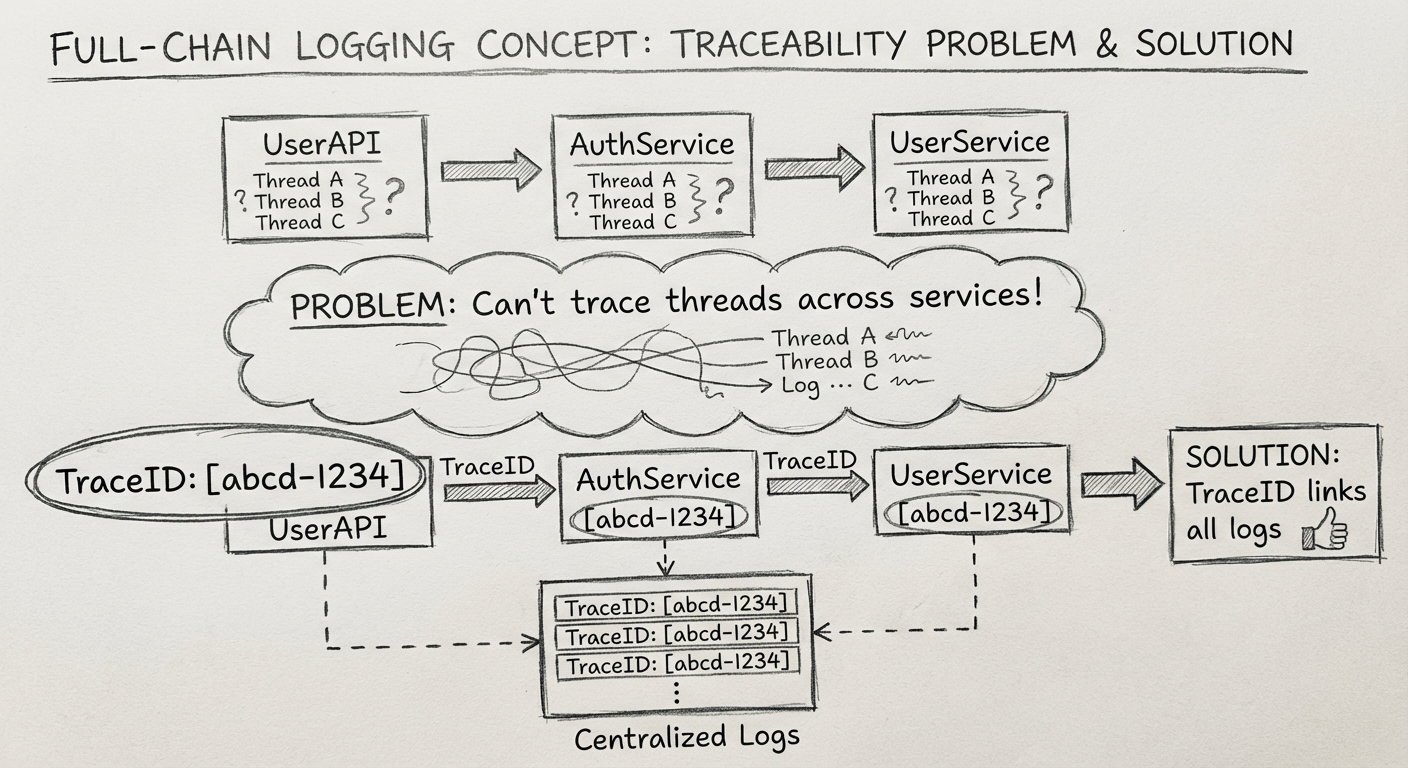
9.1 业务场景:这个请求到底经历了什么
公司某业务线刚迁移到 Spring Cloud。之前只是简单地把日志打印到本地文件,然后使用 ELK(ElasticSearch、Logstash、Kibana)进行日志收集和分析,日志记录比较随意,没有统一规范。
问题案例
有一次碰到某用户总是登录失败的问题,服务调用链路是:
UserAPI → AuthService → UserService
在 UserAPI 中还能根据用户名和线程 ID 找到相关日志。但是要去 AuthService 查找下一个服务的日志时就复杂了:
- 同一时间点有多个服务器节点
- 每个节点有多个线程 ID 在活动
- 无法判断哪个服务器的哪个线程 ID 是处理这次请求的
最终调查到的问题根源是:UserAPI 调用 AuthService 时,有个参数因为含有特殊字符被 Tomcat 自动摒弃了。
需求梳理
项目组商量后,总结了以下需求:
基础记录需求:
- 记录什么时候调用了缓存、MQ、ES 等中间件,在哪个类的哪个方法中耗时多久
- 记录什么时候调用了数据库,执行了什么 SQL 语句,耗时多久
- 记录什么时候调用了另一个服务,服务名是什么,方法名是什么,耗时多久
跨服务串联需求:
- 把同一个请求在全部服务中的所有记录进行串联,实现树状的记录
- 设计基于这些基础数据的查询统计功能
9.2 技术选型
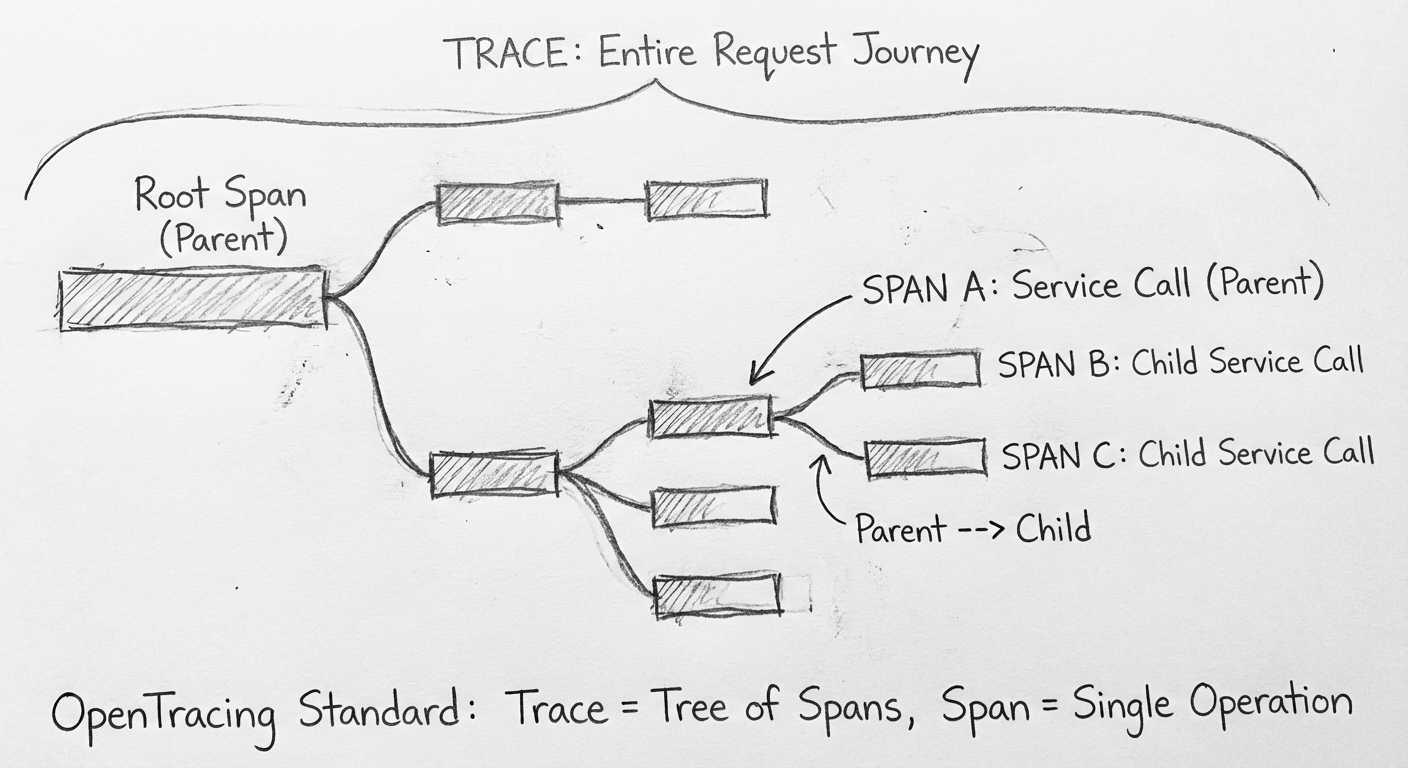
9.2.1 日志数据结构支持 OpenTracing
目前已经有一种比较通用的全链路数据格式——OpenTracing,由 Cloud Native Computing Foundation(云原生计算基金会)维护。
OpenTracing 核心概念:
| 概念 | 说明 |
|---|---|
| Trace | 一个客户端请求经历的整个流程 |
| Span | Trace 中被命名且被计时的连续性执行片段 |
| Reference | Span 与 Span 之间的关系 |
一个 Span 可以包含多个子 Span,例如:
- Order API 调用 Product Service 的整个过程是一个 Span
- Product Service 访问数据库也是一个 Span(子 Span)
必须保证系统的可替代性,尽量不要束缚于一项开源技术上。如果之前引入的全链路日志不好用,以后想换掉也非常方便。
9.2.2 支持 Elasticsearch 作为存储系统
因为流量大导致日志数据量也很大,存储系统必须支持海量数据且保证查询高效。公司运维人员对 Elasticsearch 比较熟悉。
9.2.3 保证日志收集对性能无影响
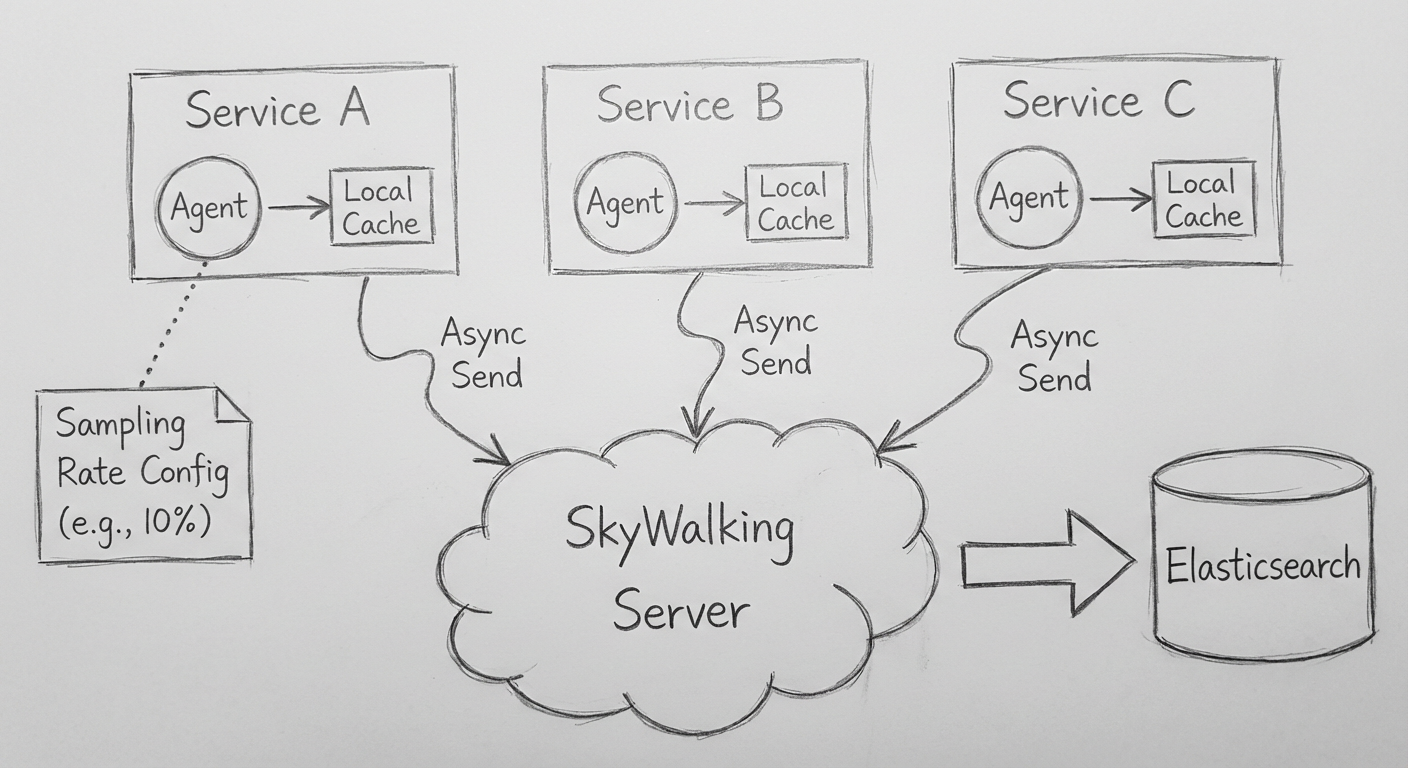
当服务在记录日志时,需要确保对服务器性能不会产生影响。
例如调研过 Pinpoint,并发数达到一定数量时整体吞吐量少了一半,这是不能接受的。
9.2.4 查询统计功能的丰富程度
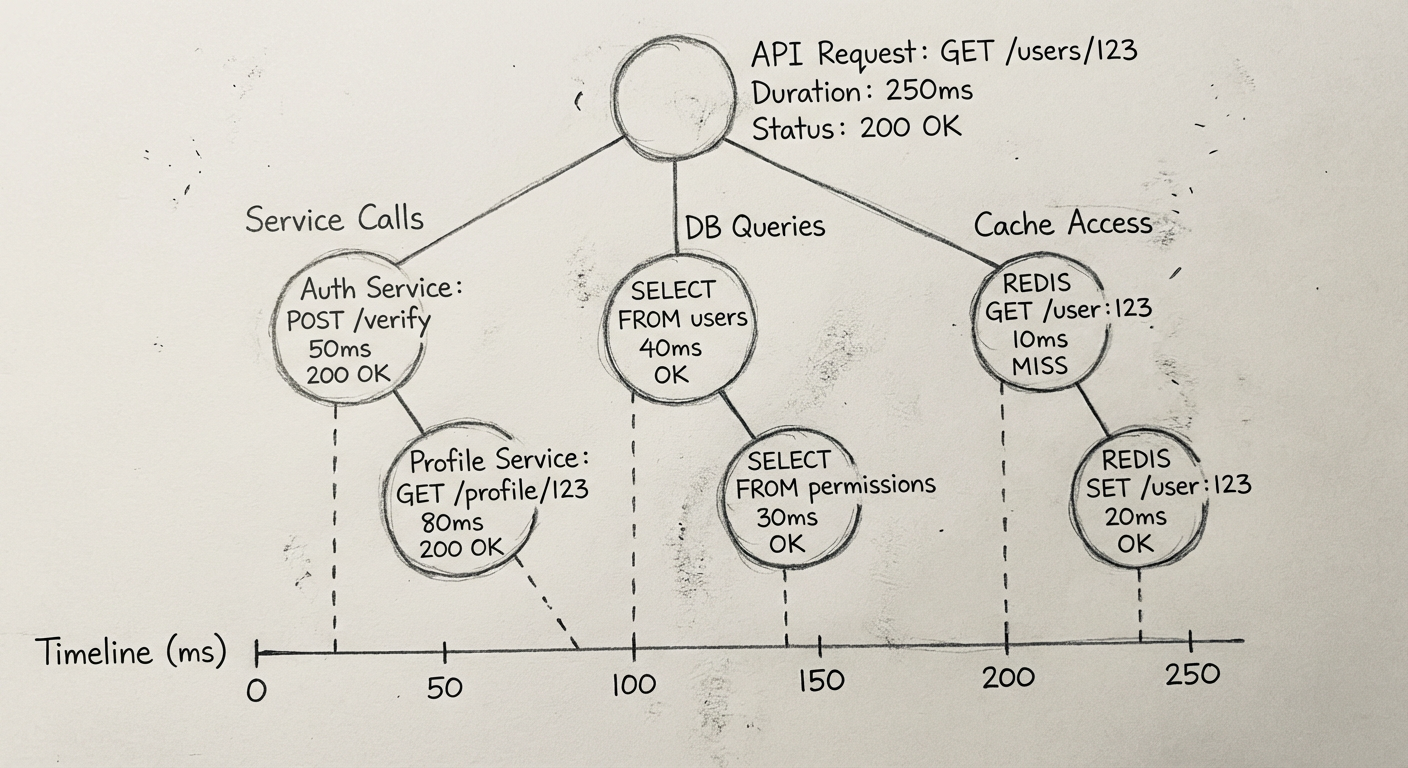
基础功能:支持每个请求树状结构的全链路日志
扩展功能:监控报警、指标统计等,减轻二次开发工作量
9.2.5 最小业务代码侵入性
希望日志数据的收集过程对写业务代码的人保持透明:
- 使用 Java 的探针,通过字节码加强的方式进行埋点
- 在封装的公共代码中实现埋点
9.2.6 最终选择:SkyWalking
根据问题剖析及性能测试结果,SkyWalking 比较符合需求:
- 500 线程压力以下的服务,是否使用 SkyWalking 对吞吐量影响不大(相差不超过 10%)
- 官方测试报告:500 并发用户,每次请求间隔 10 毫秒,TPS 基本没什么变化
- 国产开源框架,更贴近实际需求
9.3 注意事项
9.3.1 SkyWalking 的数据收集机制
日志收集过程必须是异步的,与业务流程解耦:
- 如果同步收集,业务系统和日志系统就是耦合的
- 不可能让高可用的系统依赖中可用的系统
SkyWalking 的实现:
- 服务中有一个本地缓存,先存放所有日志数据
- 后台线程通过异步的方式将缓存中的日志发送给 SkyWalking 服务端
- 日志埋点处无须等待服务端接收数据,不影响系统性能
9.3.2 如果 SkyWalking 服务端宕机了
服务端宕机后,日志缓存中的数据会出现没人消费的情况。
SkyWalking 的处理:设置缓存的大小,如果数据超出缓存大小,Trace 不会保存,不会超出内存。
9.3.3 流量较大时如何控制日志数据量
流量大时,不可能收集每个请求的日志。SkyWalking 通过采样比例控制:
agent.config:
agent.sample_n_per_3_secs: 100 # 每3秒采样100个
- 启用
forceSampleErrorSegment后,出错时会收集所有数据 - 所有相关联服务的
sampleRate最好保持一致,否则会出现一个 Trace 串不起来的情况
9.3.4 日志的保存时间
一般保存 3 个月的数据,使用 SkyWalking 直接配置即可:
core:
default:
recordDataTTL: 90 # 保存90天
9.3.5 集群配置:如何确保高可用
SkyWalking 的收集服务(Receiver)和聚合服务(Aggregator)支持集群模式,支持的协调服务包括:
- Kubernetes
- ZooKeeper
- Consul
- etcd
- Nacos
9.4 小结
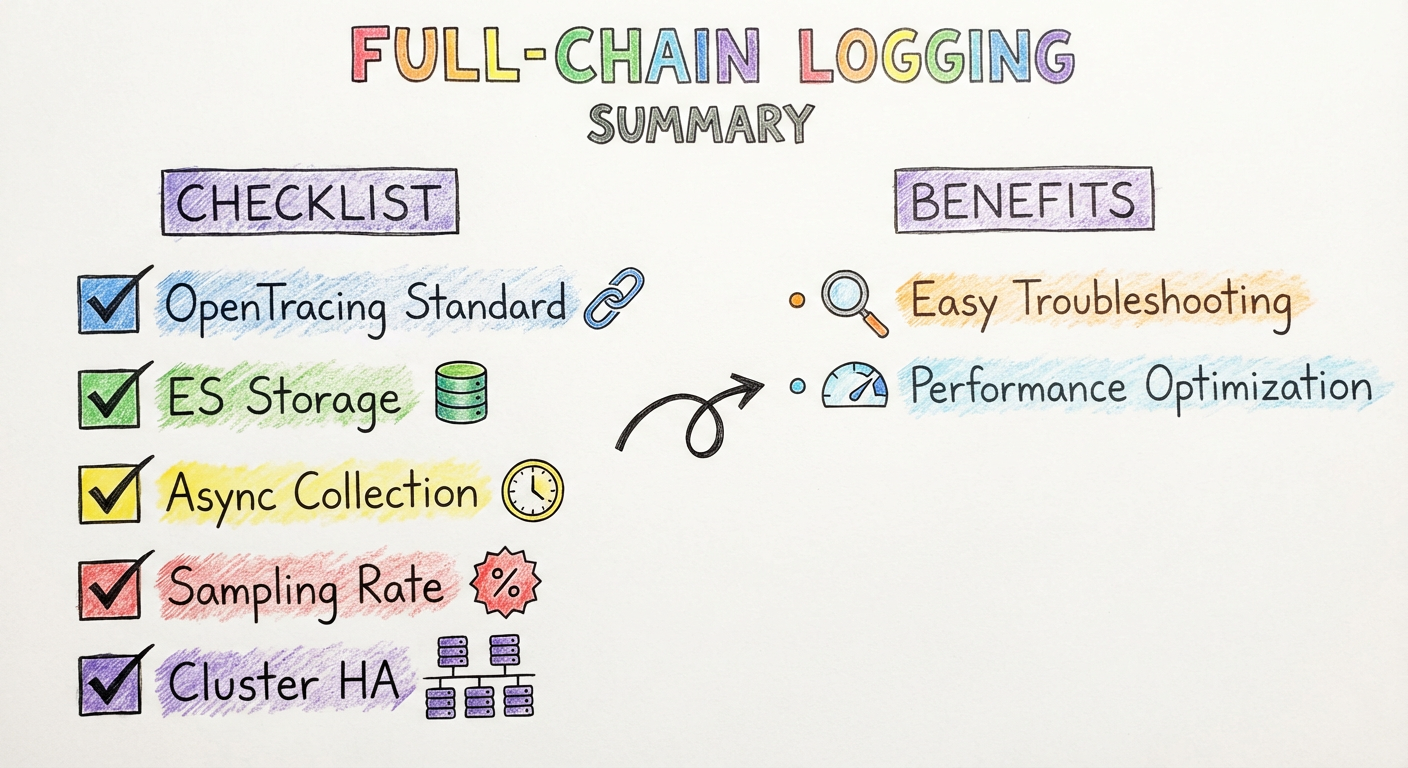
使用效果
在方案中使用 SkyWalking 后,对于问题排查帮助非常大:
- 根据关键字查到 TraceID 后,基于 TraceID 调出所有的请求日志
- 到底发生了什么一目了然
带来的收益
全链路日志系统上线后,团队优化了很多慢请求:
- 每个调用环节和耗时都列出来了
- 很容易找到瓶颈点并加以解决
- 基于这个系统,完成了多个可以汇报的亮点工作
技术选型总结
| 选型要点 | 具体内容 |
|---|---|
| 数据格式 | 支持 OpenTracing |
| 存储系统 | 支持 Elasticsearch |
| 性能影响 | 收集对性能无影响 |
| 查询功能 | 树状结构日志、监控报警 |
| 侵入性 | 最小业务代码侵入 |
这次架构经历不涉及太多的架构设计,主要是技术选型和注意事项。
接下来将讨论微服务架构中的另一个重要问题——熔断。