第8章 注册发现
本章开始进入微服务相关内容的讲解。仍然从最基础的场景入手,帮助大家快速掌握一些微服务组件的实现原理,最终理解微服务架构的本质。
8.1 业务场景:如何对几十个后台服务进行高效管理
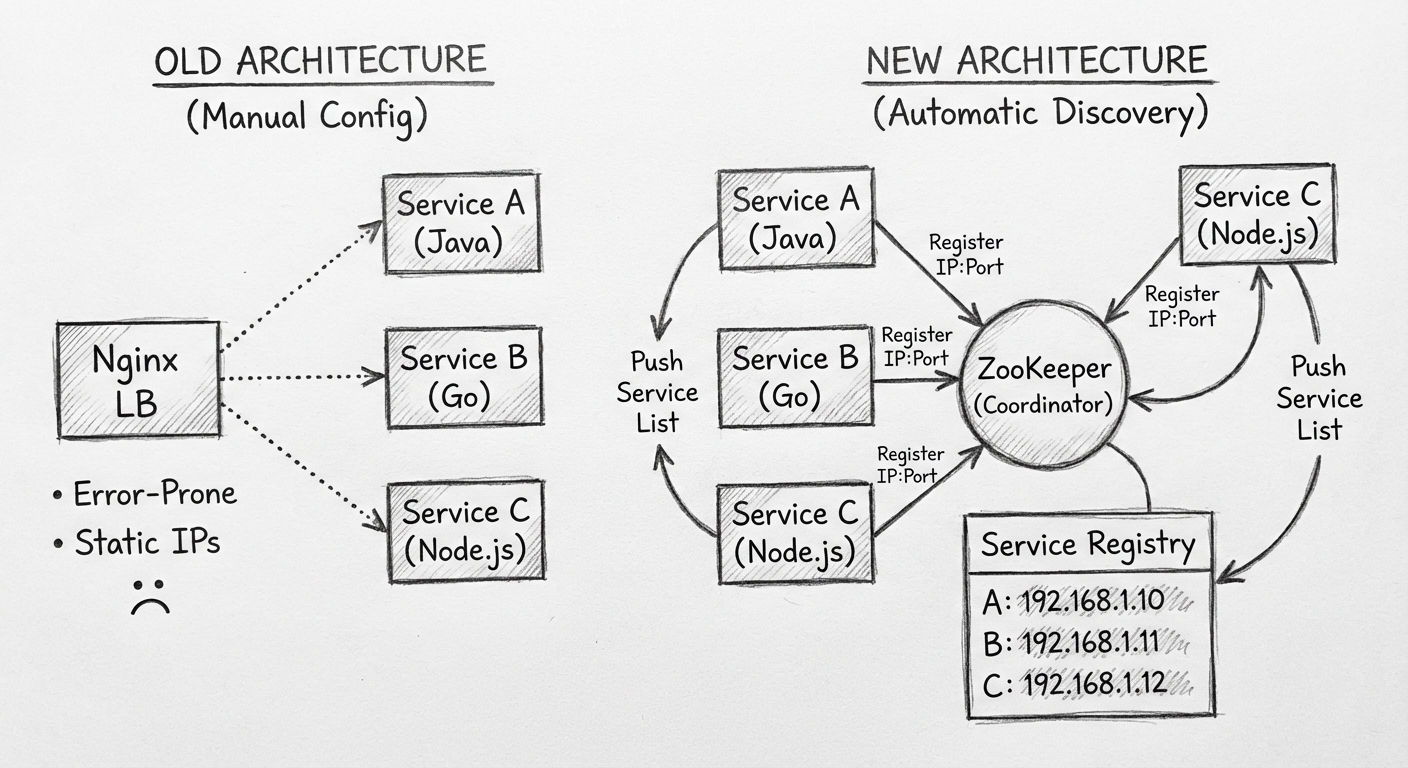
在某个系统中,已经拥有了 50多个服务,并且很多服务之间都有调用关系,而这些服务是使用各种语言编写的,比如 Java、Go、Node.js。目前流行的 Spring Cloud、Dubbo 这些微服务框架都是针对 Java 语言的,所以没有使用它们。
原有配置方式
因为这 50 多个服务都有负载均衡,所以首先需要把服务的地址和负载均衡全部配置在 Nginx 上:
upstream user-servers {
server 192.168.1.1:8080;
server 192.168.1.2:8080;
}
服务之间的调用关系主要通过本地配置文件配置,调用过程为:
- 通过本地配置文件获取需调用服务的主机地址
- 在代码中加上 URI 组装成 URL
- 所有服务之间的调用都通过 Nginx 代理
8.2 传统架构会出现的问题
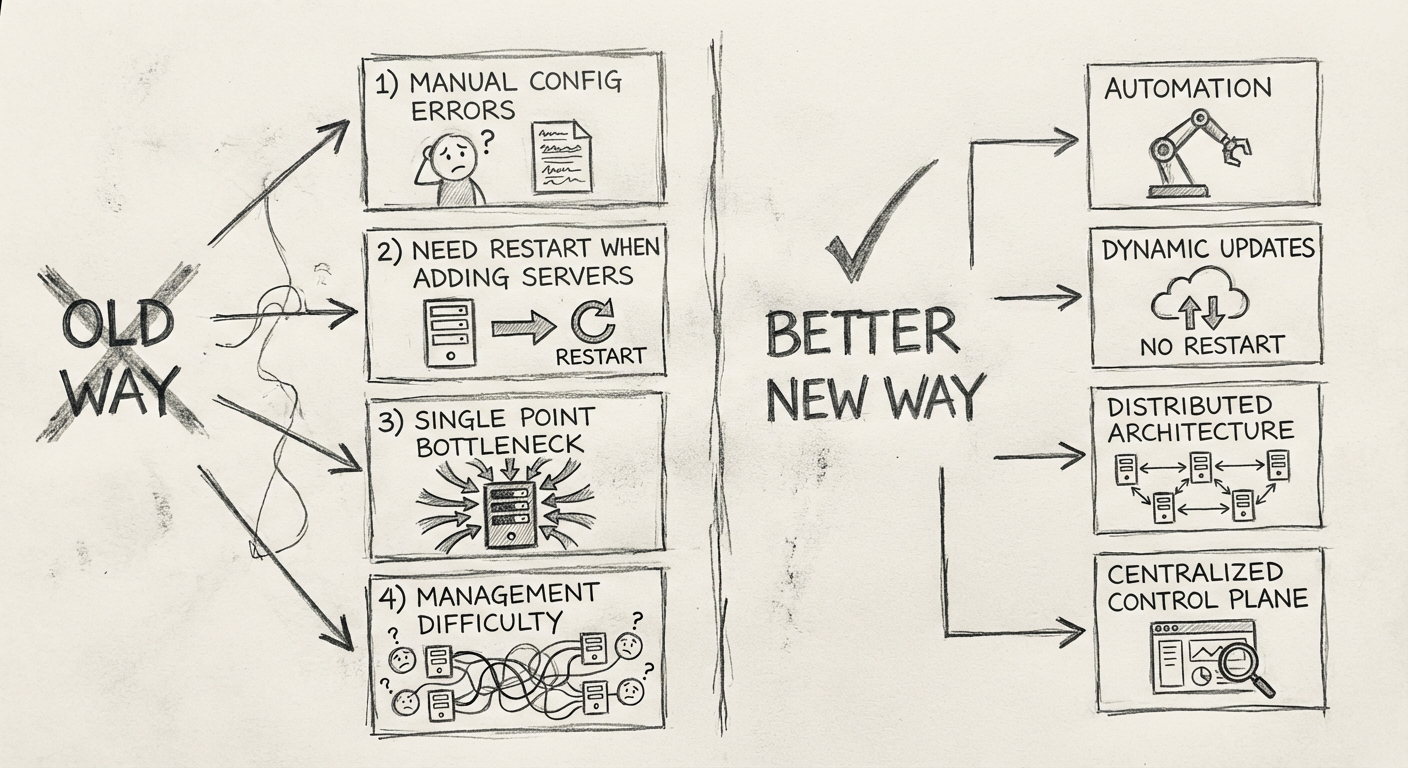
8.2.1 配置烦琐,上线容易出错
系统上线部署时,每次增服务、加机器、减机器时,Nginx 都需要手工配置,而且每个环境都不一样,所以很容易出错。
例如 user-servers 配置了两个新的 IP,需要在 4 台 Nginx 上都修改:
- 如果忘了修改其中一台,就不一定能发现
- 因为 NetScalar 可能并没有把请求导向到那台错误的 Nginx
- 这种疏忽会变成一个偶发性错误,更难被发现
8.2.2 加机器要重启
系统流量增大后,通过监控发现需要增加机器,这个过程最能考验系统的抗压性:
- 需要手工配置,稍不留神系统就会出错
- 系统一旦出错,就需要重启 Nginx
- 时间紧,又不能出错,这个过程很难
8.2.3 负载均衡单点
因为所有的服务都需要经过 Nginx 代理,所以 Nginx 很容易成为瓶颈:
- 如果 Nginx 配置出了问题,所有的服务就都不能用了
- 如果让每个服务拥有自己的 Nginx,会有很多 Nginx 需要维护,更容易出错
8.2.4 管理困难
因为合规的要求,经常需要对全系统调用库进行升级,必须有一个后台服务清单。考虑到后台服务清单都是通过手工维护的,这是个"苦力活"。
8.3 解决方案
经过讨论,团队考虑了以下 3 种解决方案:
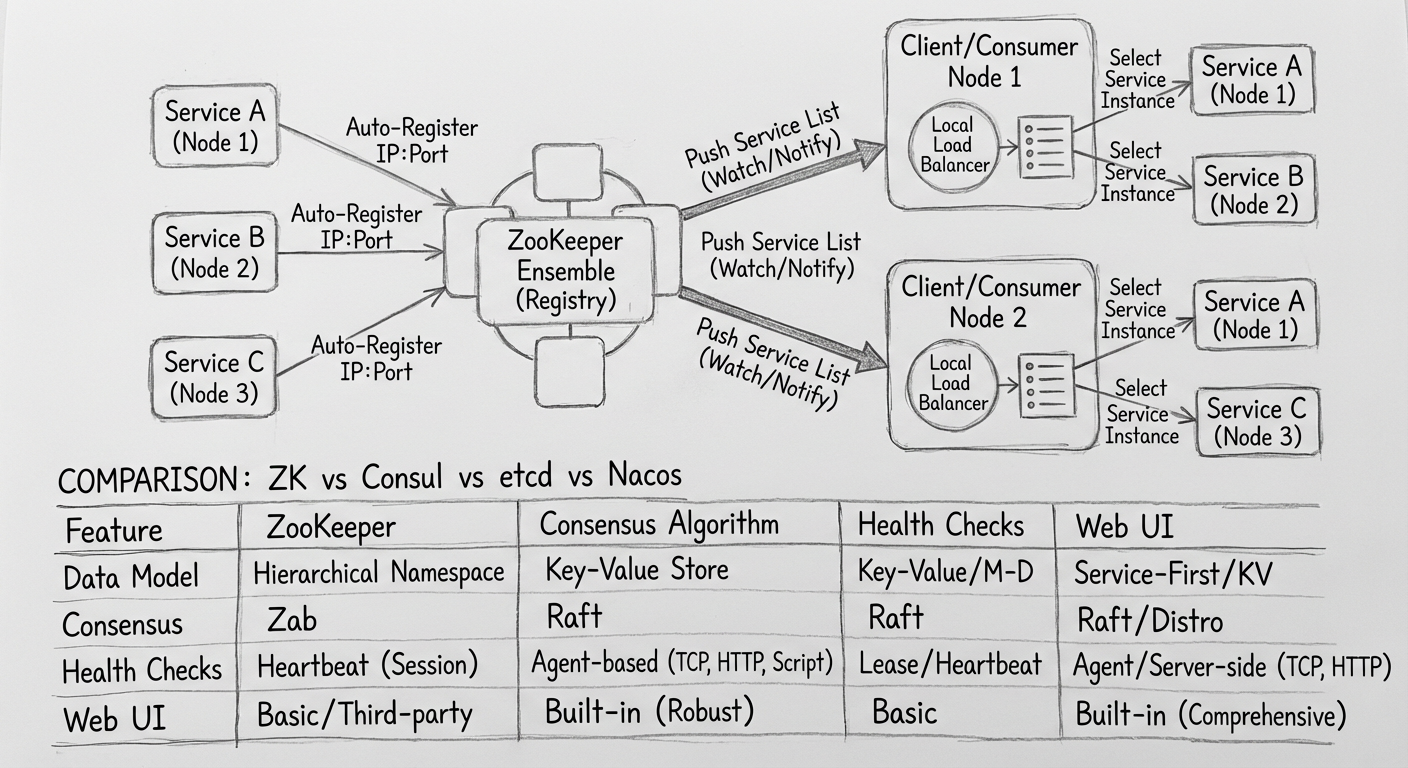
方案一:协调服务 + 本地负载均衡(最终采用)
- 每个服务自动将服务类型和 IP 注册到协调服务(如 ZooKeeper)
- 协调服务将服务列表推送到所有后台服务
- 后台服务在本地做负载均衡,轮流访问同服务的不同节点
这就是 Spring Cloud 和 Dubbo 的做法。
方案二:Kubernetes Service
将所有服务部署到容器上,利用 Kubernetes 的 Service 与 Pod 的特性:
- 在 Pod 上打上标签(如 "User-App"、"Order-App")
- 启动 Service(类似于 Nginx 的负载均衡)
- Service 自动负载均衡到相应标签的 Pod
未采用原因:团队对容器不熟悉,迁移代价和风险太大。
方案三:协调服务 + 自动更新 Nginx
设计工具自动获取 ZooKeeper 中的服务器列表,自动更新 Nginx 配置后重启。
未采用原因:没有解决 Nginx 单点瓶颈、加机器需要重启的问题。
8.4 新架构要点
8.4.1 中心存储服务使用什么技术
需要考虑以下两个需求:
- 实时推送:服务变更需要实时推送给所有后台服务
- 状态监听:随时监听所有后台服务的状态,如果宕机及时通知其他服务
分布式协调服务这个中间件刚好能全部满足。
8.4.2 使用哪个分布式协调服务
| 协调服务 | 一致性 | 配置中心 | 推荐场景 |
|---|---|---|---|
| ZooKeeper | CP | 不支持 | 已有 ZooKeeper 的公司 |
| Eureka | AP | 不支持 | Spring Cloud 生态 |
| Nacos | AP/CP 可配置 | 支持 | 新项目(推荐) |
| Consul | CP | 支持 | Go 语言生态 |
推荐 Nacos 的原因:
- 带有配置中心功能,一个中间件相当于两种
- 在一致性里面满足 AP 和 CP,其他中间件只满足其一
8.4.3 基于 ZooKeeper 需要实现的功能
- 服务启动时,将信息注册到 ZooKeeper
- 将所有后台服务信息从 ZooKeeper 拉取下来
- 监听 ZooKeeper 事件,如果后台服务信息变更就更新本地列表
- 调用其他服务时,实现负载均衡策略(一般用轮询/Ribbon)
8.5 ZooKeeper 宕机了怎么办

ZooKeeper 本身为了一致性牺牲了高可用性,如果 Leader 或半数的 Follower 宕机,ZooKeeper 就会进入漫长的恢复模式,在这段时间里不接受客户端任何请求。
CAP 原则
| 特性 | 说明 |
|---|---|
| 一致性(C) | 分布式系统中所有数据副本在同一时刻是否一致 |
| 可用性(A) | 集群中一部分节点故障后,集群整体是否还能响应请求 |
| 分区容错性(P) | 节点之间网络出问题时,如何处理数据不同步 |
ZooKeeper 宕机的 3 种情况
| 情况 | 影响 |
|---|---|
| 本地已缓存服务清单 | 影响较小,只需保证期间没有服务器变更 |
| 期间服务器变更 | 可能出现调用失败 |
| 服务在恢复期间启动 | 连不上 ZooKeeper,获取不到服务清单(最坏情况) |
解决方案
每次通过某个特定服务把所有服务清单同步一份到配置中心,新的后台服务获取不到服务清单时,再从配置中心获取。
在微服务间协调这个场景里面,AP 比 CP 更合适,所以 Eureka 比 ZooKeeper 更适合。而 Nacos 可以通过配置来选择 AP 或 CP。
8.6 小结

解决的问题
| 原问题 | 解决方案 |
|---|---|
| 配置烦琐,上线容易出错 | 后台服务自动连接 ZooKeeper 注册 IP |
| 加机器要重启 | 新机器自动注册 IP,ZooKeeper 无需重启 |
| 负载均衡单点 | ZooKeeper 集群具有高可用性 |
| 管理困难 | 所有后台服务类型和 IP 可直接查询 |
额外收益
少了两层(NetScalar 和 Nginx)的网络通信,性能也提高了。
方案不足
这次架构经历有点类似于自己造轮子,因为注册发现是 Spring Cloud 或 Dubbo 已经实现的功能。不过重复造轮子的好处是能对微服务中服务注册发现的原理了解得更加透彻。
有些公司的做法是直接用 Kubernetes 的 Service 功能来解决,因为他们的运维人员对容器已经很熟悉了。
接下来将讨论微服务架构中让人诟病的另一个问题——全链路日志。