第14章 数据同步
上一章讲解了数据一致性的解决方案,这一章来讲讲服务之间的数据依赖问题,还是先来说说具体的业务场景。
14.1 业务场景:如何解决微服务之间的数据依赖问题
在某个供应链系统中,存在商品、订单、采购这 3 个服务,它们的主数据部分结构表如下:
1. 商品表
| 字段 | 说明 |
|---|---|
| 商品ID | 主键 |
| 商品名称 | - |
| 商品分类ID | 外键 |
| 生产批号ID | 外键 |
| 其他字段... | - |
2. 订单表和子订单表
| 字段 | 说明 |
|---|---|
| 订单ID | 主键 |
| 商品ID | 关联商品 |
| 其他字段... | - |
3. 采购单表和采购子订单表
| 字段 | 说明 |
|---|---|
| 采购单ID | 主键 |
| 商品ID | 关联商品 |
| 其他字段... | - |
业务需求
- 根据商品的型号、分类、生成年份、编码等查找订单
- 根据商品的型号、分类、生成年份、编码等查找订单或采购单
初期方案设计
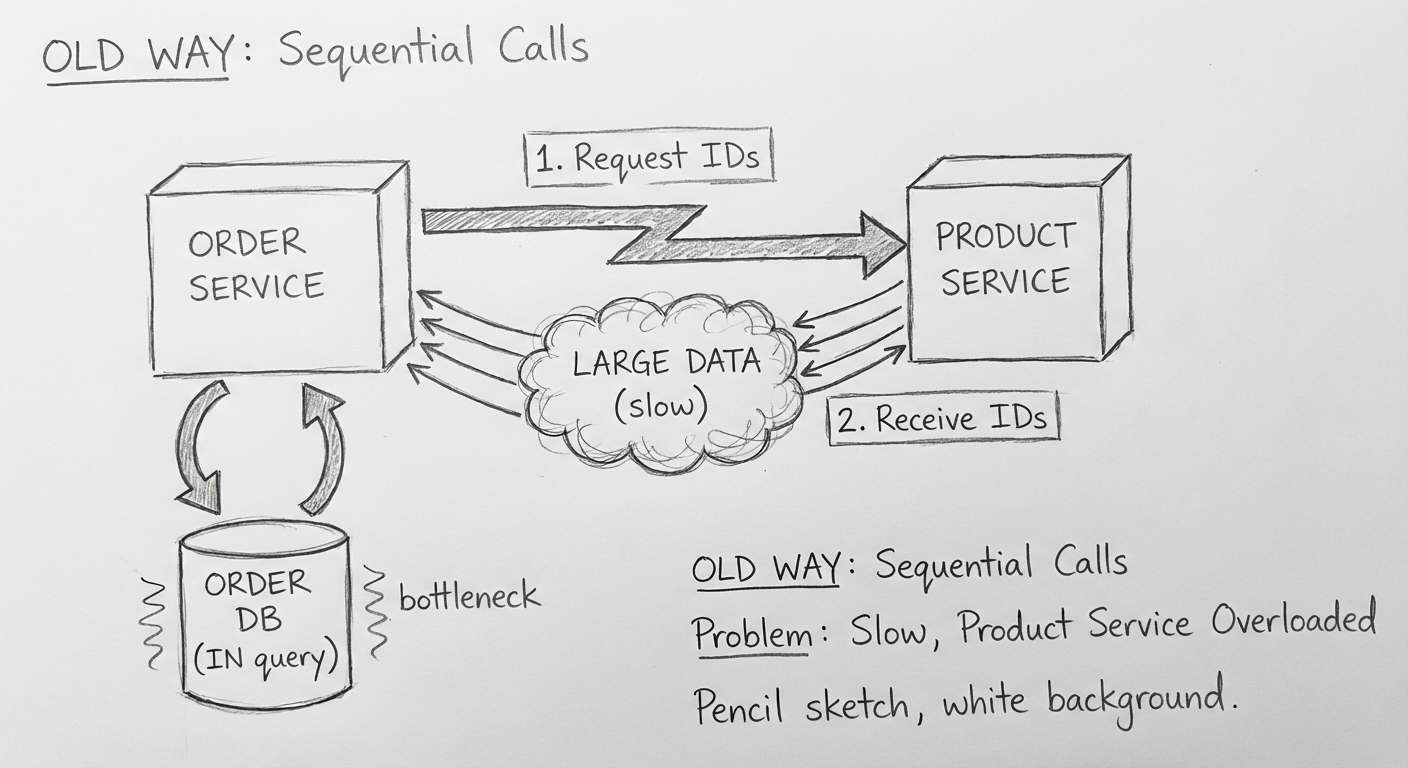
按照严格的微服务划分原则,把商品相关的职责放在商品服务中,所以在订单与采购单查询过程中,如果查询字段包含商品字段,就按照如下顺序进行查询:
- 先根据商品字段调用商品服务,然后返回匹配的商品信息
- 在订单服务或采购服务中,通过 IN 语句匹配商品 ID,再关联查询对应的单据
遇到的问题
初期方案设计完成后,很快就碰到了一系列问题:
| 问题 | 说明 |
|---|---|
| 查询效率低 | 随着商品数量增多,匹配到的商品越来越多,IN 语句查询效率越来越低 |
| 商品服务超负荷 | 作为核心服务,依赖它的服务越来越多,商品服务开始不堪重负 |
| 请求失败 | 因为商品服务超时,使得依赖它的服务处理请求也经常失败 |
这就导致业务方查询订单或者采购单时,每次只要加上商品 ID 这个关键字,查询效率就会很低,而且经常失败。
14.2 数据冗余方案
于是团队想出了一个新的方案——冗余。
数据冗余方案即在订单、采购单中保存一些商品的字段信息:
| 订单表新增字段 | 说明 |
|---|---|
| 商品分类ID | 冗余自商品表 |
| 商品型号 | 冗余自商品表 |
| 生产批号 | 冗余自商品表 |
通过这样的方案,每次查询订单或采购单时,就不需要依赖商品服务了。
冗余数据同步的两种方式
商品如果有更新,怎么同步冗余的数据呢?
方式一:同步调用
每次更新商品时,先调用订单与采购服务,然后更新商品的冗余数据。
问题:
- 数据一致性问题:如果冗余数据更新失败,整个操作要回滚,冗余数据并不是商品服务的核心需求
- 依赖问题:商品服务需要调用订单、采购、门店库存、运营等众多服务,与底层服务的初衷相悖
结论:直接被否决。
方式二:消息发布订阅
每次更新商品时,发布一条消息,订单与采购服务各自订阅这条消息,再各自更新商品的冗余数据。
好处:
- 商品无须再调用其他服务,它只需要关注自身的逻辑,最多生成一条消息到 MQ
- 如果订单、采购等服务的冗余数据更新失败了,只需要使用消息重试机制就可以保证数据的一致性
消息订阅方案的问题
这个方案已经比较完善了,但存在以下几个问题:
| 问题 | 说明 |
|---|---|
| 冗余数据需要更新 | 每个服务需要订阅商品变更、商品分类、商品生产批号等近 10 种消息 |
| 重复实现同步逻辑 | 采购、订单及其他服务都需要依赖商品数据,每个服务都需要把冗余数据的订阅、更新逻辑做一遍 |
| MQ 消息类型过多 | 消息联调比接口联调更麻烦,经常不知道某条消息被哪台服务节点消费了 |
因为并不希望出现这么多消息,特别是冗余数据这种非核心需求,最终项目组决定使用一个特别的同步冗余数据的方案。
14.3 解耦业务逻辑的数据同步方案
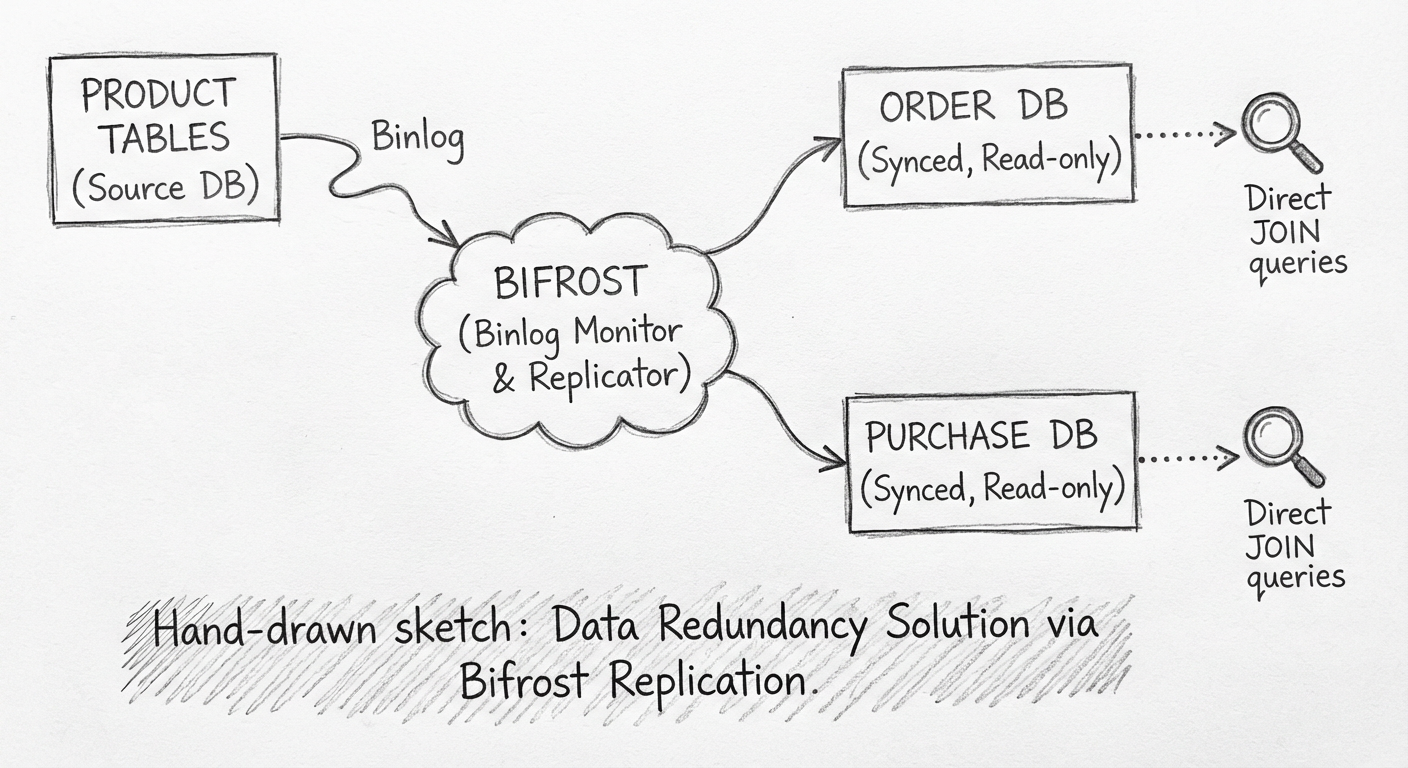
解耦业务逻辑的数据同步方案设计思路是这样的:
- 将商品及商品相关的一些表(比如分类表、生产批号表、保修类型、包换类型等)实时同步到需要依赖和使用它们的服务的数据库,并且保持表结构不变
- 在查询采购、订单等服务中的数据时,直接关联同步过来的商品相关表
- 不允许采购、订单等服务修改商品相关表
方案优势
以上方案能轻松避免以下两个问题:
- 商品无须依赖其他服务,如果其他服务的冗余数据同步失败,它也不需要回滚自身的流程
- 采购、订单等服务无须关注冗余数据的同步
存储空间对比
| 方案 | 存储空间消耗 |
|---|---|
| 数据冗余方案 | 1000 万条订单 × 商品冗余数据 = 1000 万条冗余数据 |
| 数据同步方案 | 只增加 10 万条商品数据 |
结论:数据同步方案更省空间。
14.4 基于 Bifrost 的数据同步方案
14.4.1 技术选型
项目组决定找一个开源中间件,需要满足以下 5 点要求:
| 要求 | 说明 |
|---|---|
| 支持实时同步 | 数据变更后立即同步 |
| 支持增量同步 | 只同步变化的数据 |
| 不用写业务逻辑 | 无侵入性 |
| 支持 MySQL 之间的同步 | 符合技术栈 |
| 活跃度高 | 有持续维护 |
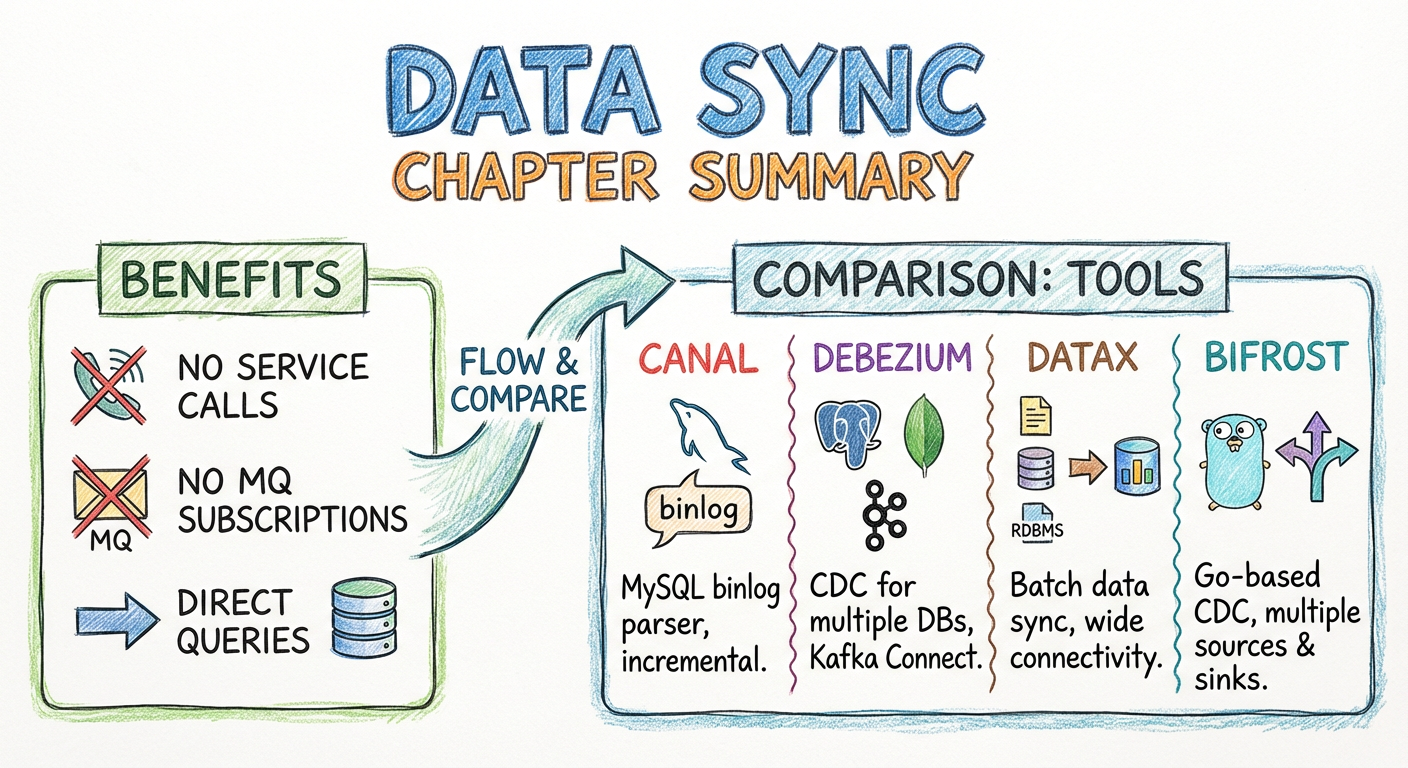
中间件对比
| 中间件 | 实时同步 | 增量同步 | 无业务逻辑 | MySQL同步 | 活跃度 |
|---|---|---|---|---|---|
| Canal | ✓ | ✓ | ✓ | ✓ | 高 |
| Debezium | ✓ | ✓ | ✓ | ✓ | 高 |
| DataX | ✗ | ✓ | ✓ | ✓ | 中 |
| Bifrost | ✓ | ✓ | ✓ | ✓ | 中 |
选择 Bifrost 的原因
Bifrost 是一个相对比较年轻的中间件,而且它不支持集群。为什么使用它呢?
| 原因 | 说明 |
|---|---|
| 界面管理方便 | 可视化配置和管理 |
| 架构简单 | 出现问题后可以自己调查,相对比较可控 |
| 作者更新活跃 | 持续维护中 |
| 自带监控报警功能 | 方便运维 |
14.4.2 Bifrost 架构
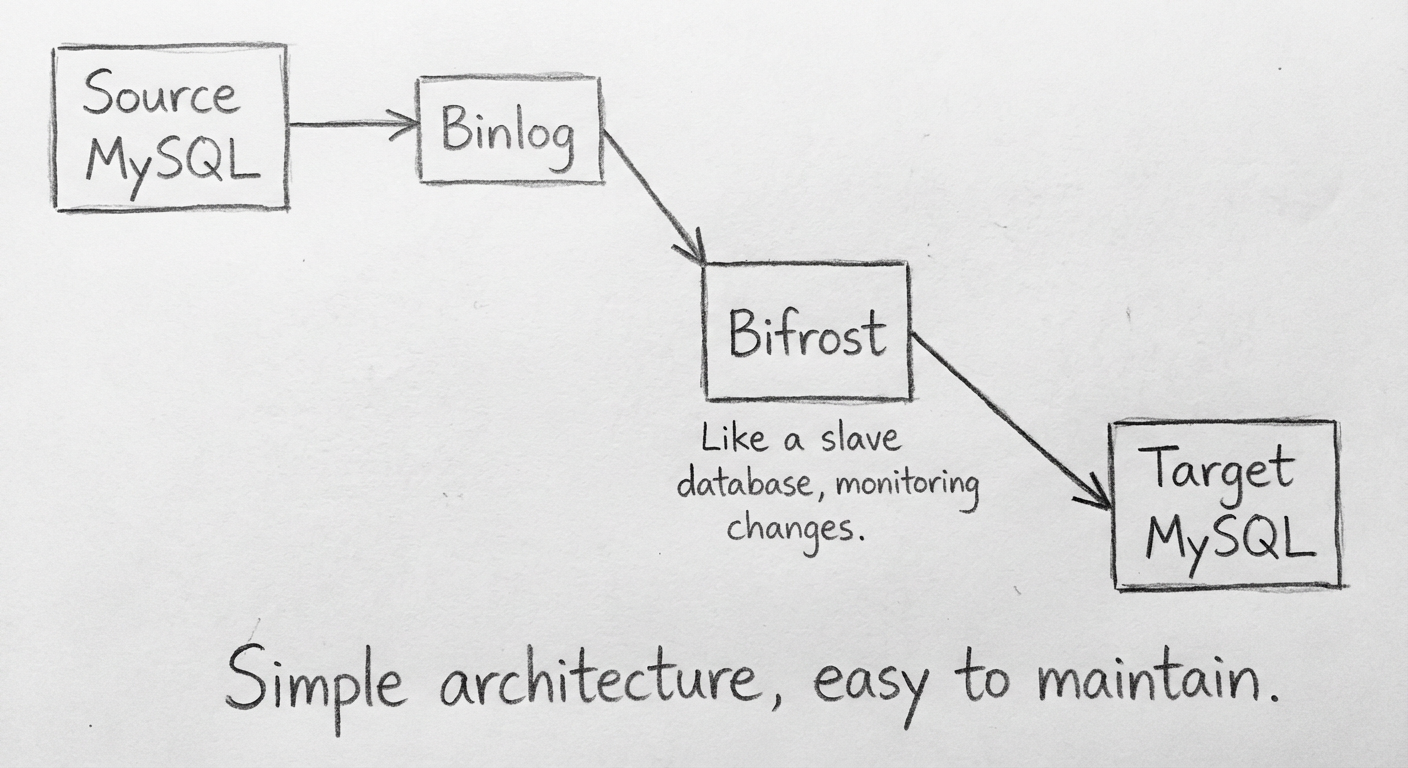
Bifrost 其实也是模拟成 MySQL 的从库,监听源数据库的 Binlog,然后再同步到目标数据库。
它支持多种目标数据库,本项目是从 MySQL 同步到 MySQL。
14.4.3 注意事项
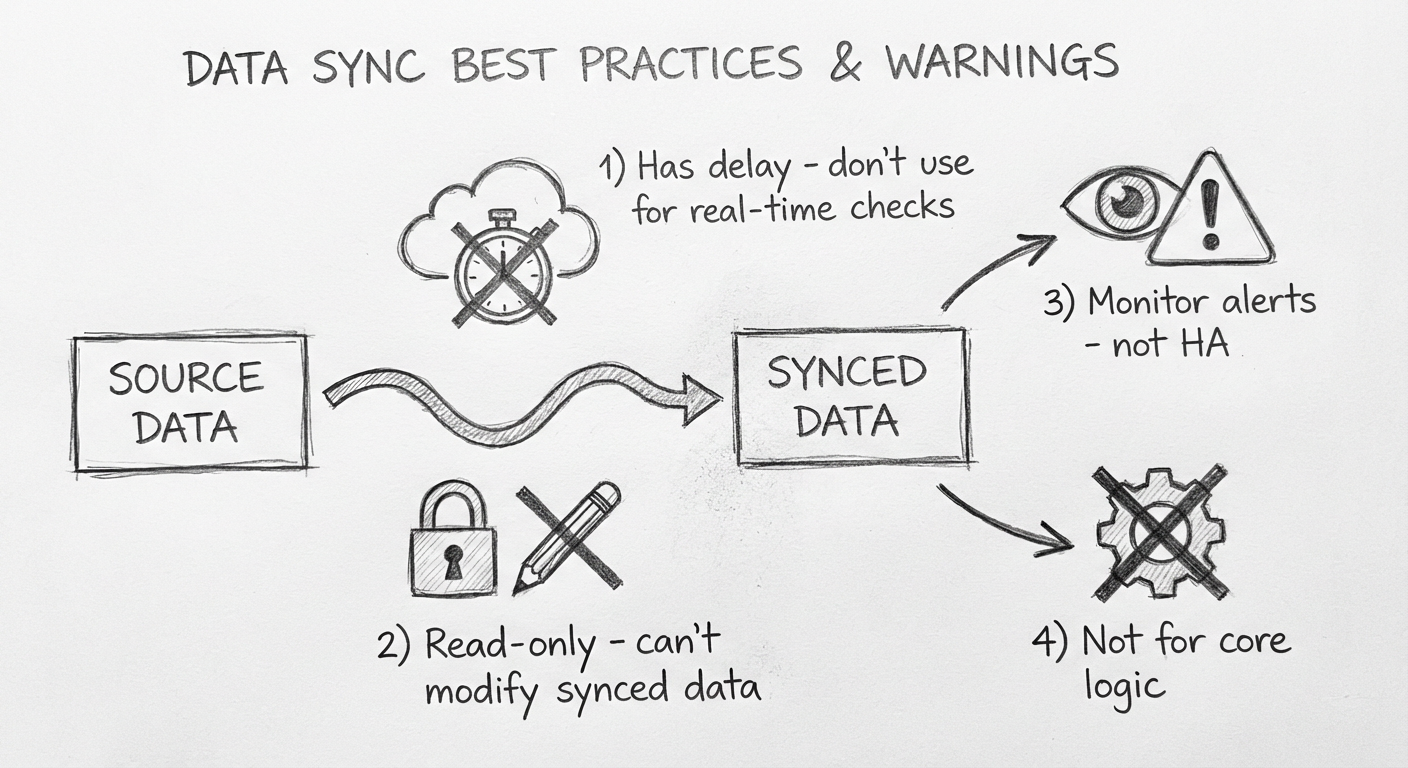
使用数据同步这个方案时,应该注意什么?
1. 数据同步的延时
这个数据同步方案是有一定延时的,所以如果业务对同步功能有高时效的要求,那么尽量不要使用这个方案。
示例:虽然同步了商品的数据到订单数据库,但是订单服务当中,如果提交订单需要检查库存的话,不建议把库存数据同步到订单数据库里,而是让订单服务每次都去请求商品数据库的库存。
同步过来的数据基本上只是用来展示、查询的,不涉及业务数据变更。
2. 同步过来的数据是只读的
因为这里的数据同步是单向的,所以目标数据库中同步过来的数据是不能修改的。
如果发现同步数据有遗漏(比如城市/区/县数据),也不能直接在业务数据库里修改,而是应该通知提供数据的系统去修改,之后再同步过来。
3. 监控一定要到位
Bifrost 不是高可用的,它本身也提供了一些告警的功能。除了依赖它本身的告警功能以外,还要额外监控 Bifrost 这个服务的状态,确保它出现异常时能及时发现。
Bifrost 本身也提供了 API 接口,用来让第三方的监控对接。
4. 核心逻辑不建议依赖同步数据
因为同步过来的数据是有延时的,并且 Bifrost 本身没有设计高可用,所以并不推荐在核心逻辑上使用同步的数据。
核心逻辑示例:
- 订单提交前需要检查库存 → 应该直接去访问查询库存的服务
- 权限的检查 → 不推荐把权限数据直接同步到业务系统
14.5 小结
方案对比
| 方案 | 优点 | 缺点 |
|---|---|---|
| 初期方案(跨服务查询) | 实现简单 | 性能差,依赖重 |
| 数据冗余方案 | 查询快 | 需要维护同步逻辑,消息多 |
| 数据同步方案 | 无业务侵入,自动同步 | 有延时,只读 |
实施效果
系统上线后,商品数据的同步比较稳定:
- 商品服务的开发人员:只需要关注自己的逻辑,无须关注使用数据的人
- 采购服务的开发人员:不需要关注商品数据的同步问题,只需要在查询时加上关联语句即可
算是一个双赢的结局。
关于高可用
唯一遗憾的是 Bifrost 不是集群,无法应对高可用场景。不过,到目前为止,这个系统还没有出现宕机的情况,反而是那些部署多台节点负载均衡的后台服务常常出现这种情况。
Bifrost 的作者也介绍了他为什么没有设计集群:
- 在实际工作中,项目组很大一部分时间其实都是在处理线上高可用、分布式遇到的各种问题
- 很多开源系统的高可用可能并不是我们想象中的那样高可用
- 在实际工作中,绝大多数一开始就使用各种分布式、高可用设计的项目,最后都失败了
- Bifrost 是一个面向生产环境的产品,对生产环境抱有敬畏之心
高可用不一定真的高可用,单机也未必不能高可用。当然,也不能以偏概全地说高可用设计没有必要,那就因噎废食了,这种状况毕竟只是特例。
不管怎么样,项目组最终解决了服务之间数据依赖的问题。接下来,就要直接面对服务之间逻辑或流程上依赖的问题了,请看第15章 BFF。